The weather app I swore I'd never write
There is a short list of apps every developer is contractually obliged to build at least once: a to-do list, a Markdown editor, a podcast player, and — the final boss of clichés — a weather app. I held the line for twenty years. This is the confession of how I finally caved.
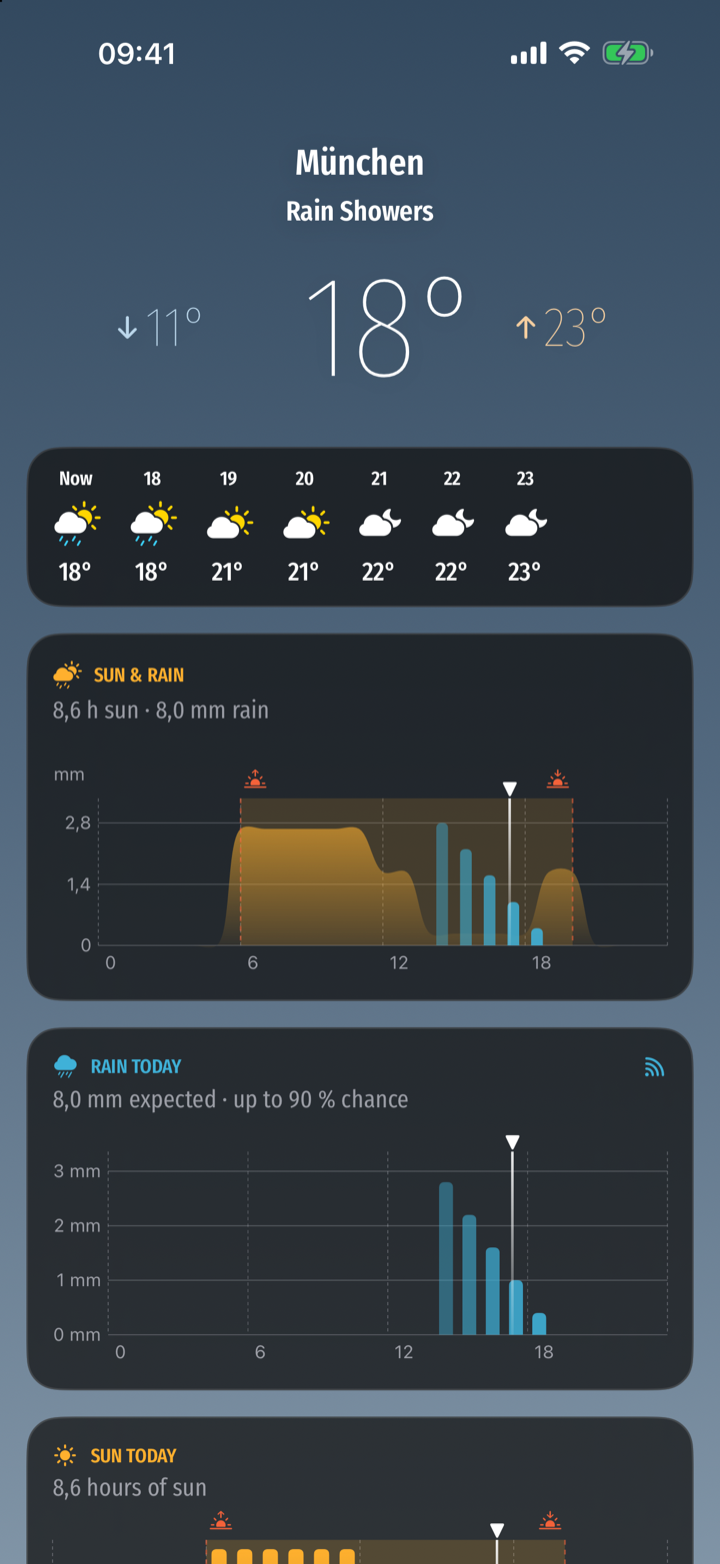
For most of those twenty years I didn’t have to, because I had WeatherPro. It wasn’t the very first app I bought — but it was one of the early ones, and it has been on the App Store since 2009, which in App Store years is roughly the Pleistocene. For the better part of seventeen years it did exactly one thing and did it beautifully: it told me whether to take a jacket. We grew old together. The trouble is that only one of us aged gracefully. Somewhere along the line of modern iOS releases it started to feel like a museum piece running behind glass — slow to launch, occasionally confused about where I am, visibly held together by the heroic but finite patience of whoever still maintains it. Every update was a small prayer that it would survive the next one.
So I did the reasonable thing first: I went looking for a replacement. I will spare you the full ethnography of the modern weather-app store, but the highlights were an app that wanted an account to show me the temperature, one that had grown a chat assistant nobody asked for, and several that were, structurally, a banner ad with a thin film of meteorology on top. I wanted the sky at a glance. The market offered me a loyalty programme.
You know exactly what happened next, because you would have done the same. I thought the four most expensive words in software — how hard can it be? — and opened Xcode.
It is, of course, harder than it looks
The data was the easy part. Open-Meteo serves genuinely good forecast data, for free, with no key and no account, under a friendly licence. That alone removed about 80% of the reasons the other apps are the way they are. The remaining 20% was the part I actually cared about: making the sky legible.
The centrepiece is a chart that puts the two things you actually want to know — is it sunny, and is it going to rain — into one picture: sunshine as a soft area, rain as bars, framed by sunrise and sunset, with a marker for now.
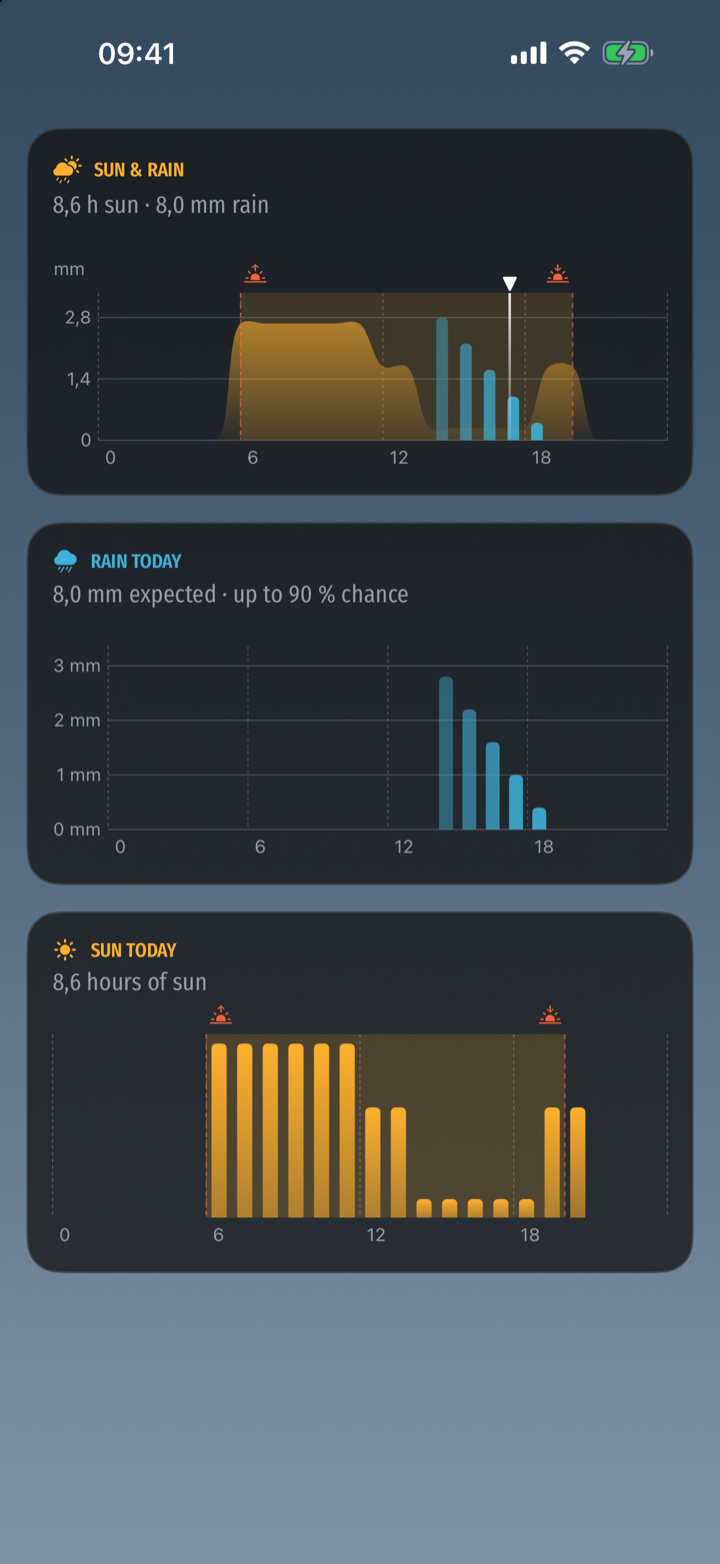
I will admit there is a small, knowing crime in that chart: the y-axis is labelled in millimetres of rain, and the sunshine curve cheerfully shares it without having any honest business being measured against it. I went back and forth on this for an embarrassingly long time before deciding that a glance card is allowed to be impressionistic, and that meteorological honesty can live ten pixels lower in the two detail charts. This is, as ever, the other 90 percent of the work: nobody will ever see the afternoon I spent on the smoothness of one shoulder of one curve.
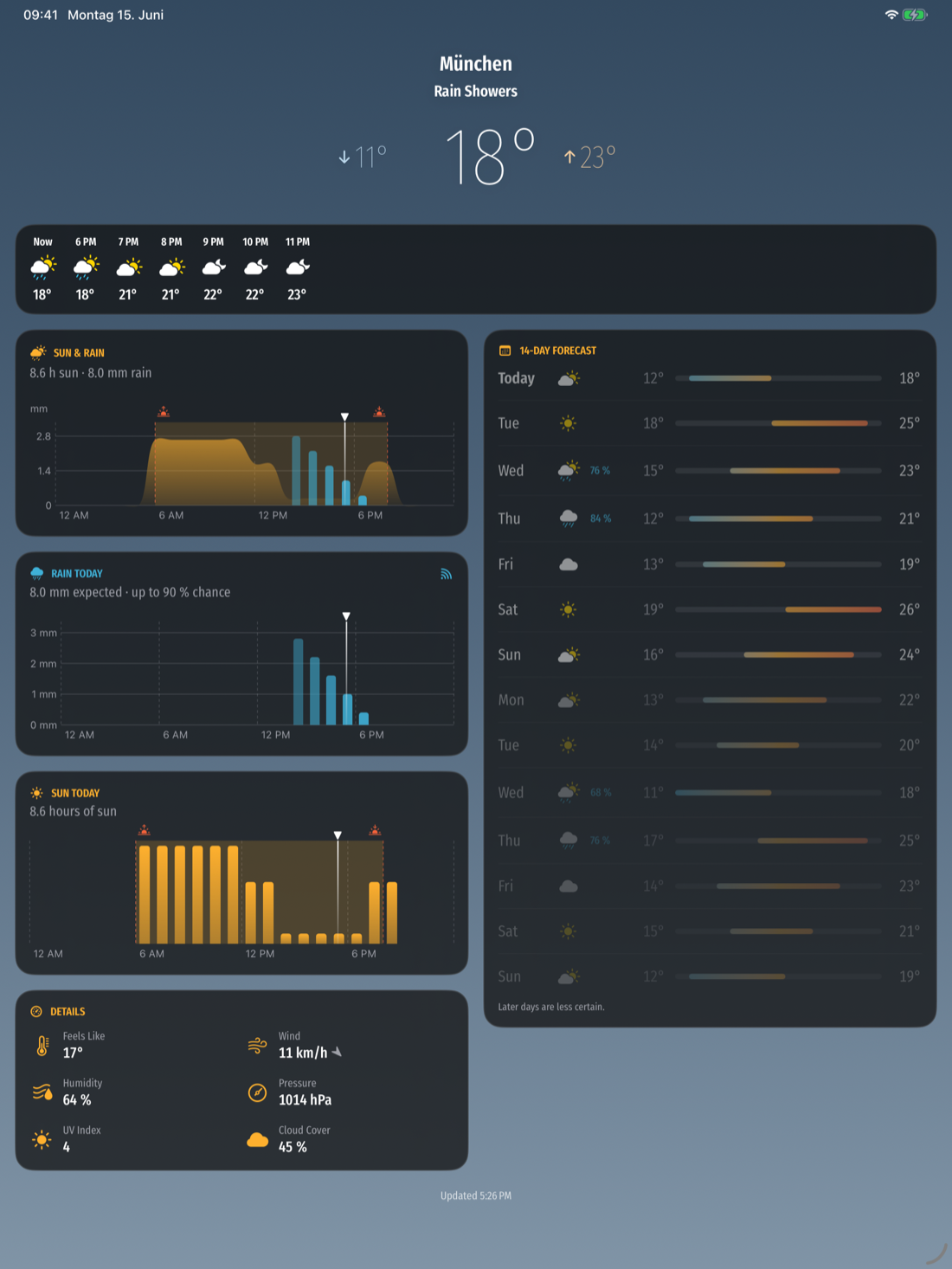
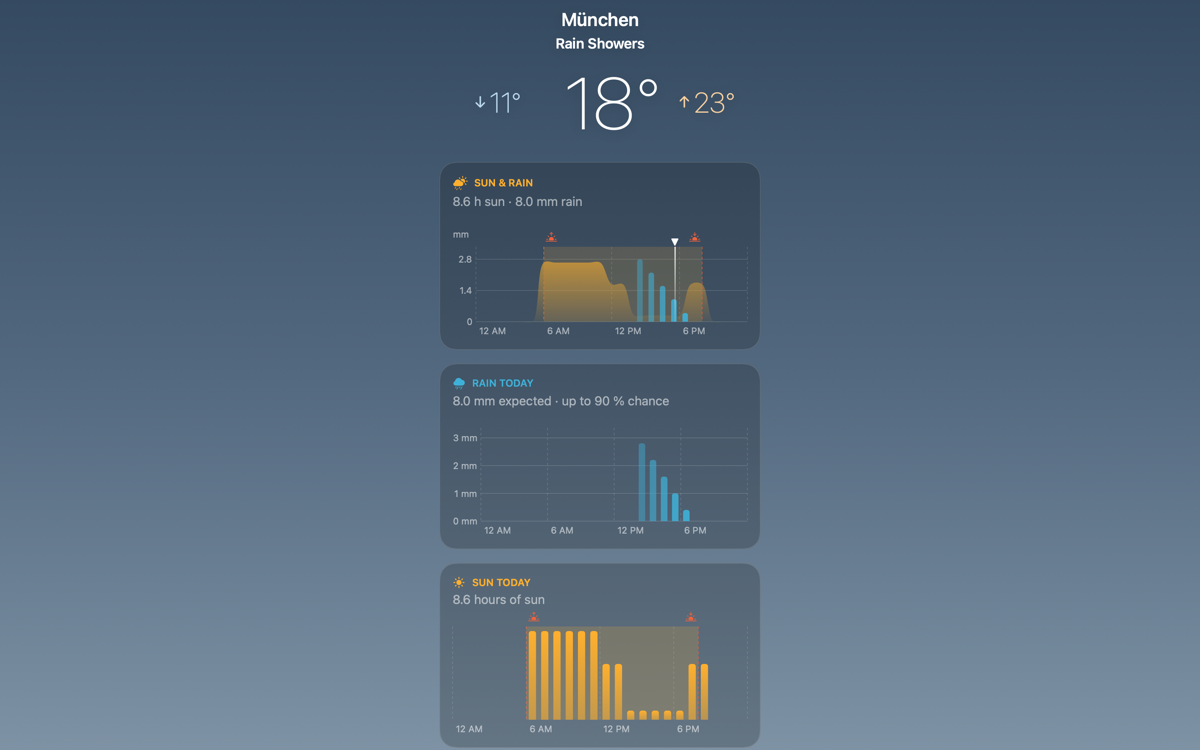
One forecast, four screens
Because I have apparently learned nothing, SunDog isn’t just an iPhone app. It’s also on iPad, where the extra room earns a proper two-column layout:
…on the Mac, as a menu-bar app that drops the whole forecast into a popover, because the natural habitat of a weather check is the corner of your screen, not a Dock icon:
…and on the Apple Watch, reduced to the one question a wrist is good for — what is it doing now, and what’s it about to do:
About the name
A sundog — a parhelion — is a real thing: two bright spots that flank the sun when light refracts through ice crystals high in the sky. It is the kind of small, easy-to-miss wonder you only catch if something nudges you to look up. When the conditions are right, the app quietly suggests exactly that. It seemed like a fitting name for software whose entire ambition is to make you glance at the sky and then put the phone away.
SunDog is free, has no account, no ads, and no tracking, and it will stay that way. It’s in TestFlight now while I sand down the last of that 90 percent; the public release follows once I trust it with your jacket decisions.
And WeatherPro? It’s still on my home screen. Some loyalties you keep even after you’ve replaced the thing they were for.
The other 90 percent — polishing notes from a streaming-radio app
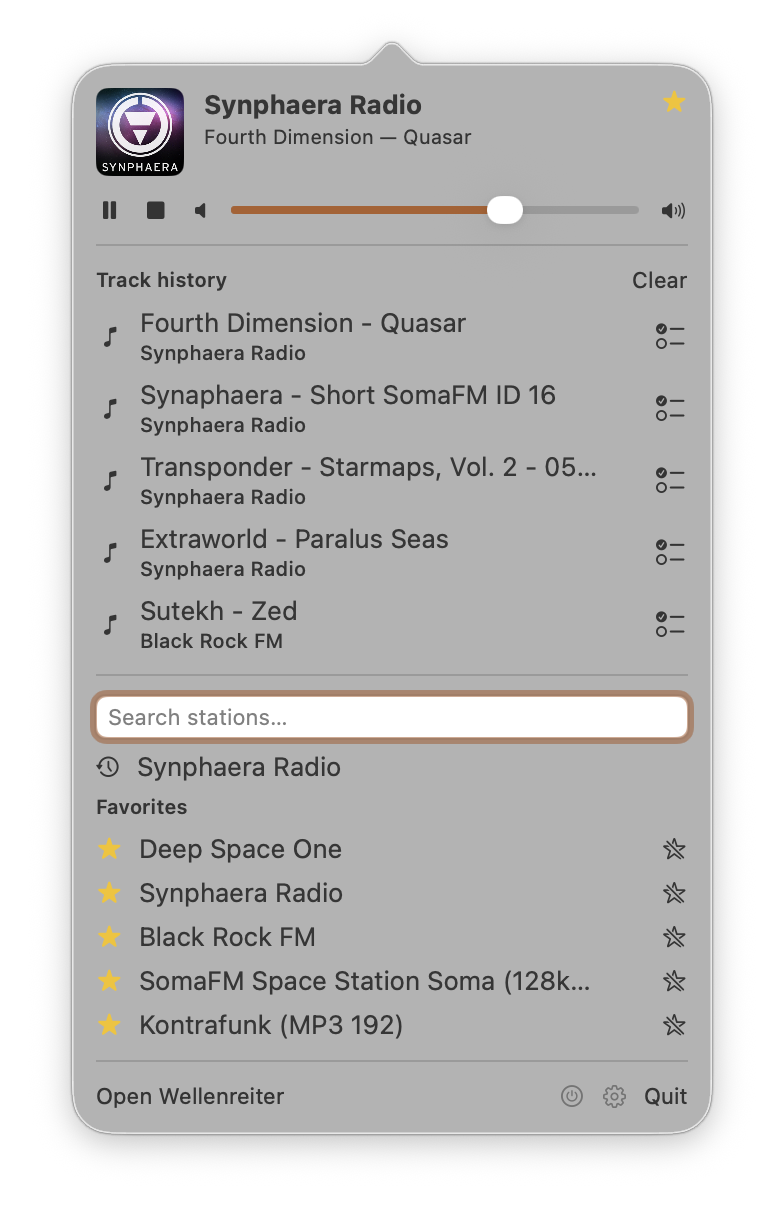
I have been polishing Wellenreiter — my streaming-radio app for iOS, iPadOS, macOS, and CarPlay — for the better part of a year. The newest addition is a standalone macOS menu-bar app: the whole experience in a popover that opens on a global hotkey. The feature list is short and unremarkable: it plays internet radio, has favourites, has search. That part took a few weeks. Almost everything since has been the other 90 percent — the work that never shows up on a feature comparison but that you feel the moment you start using the app every day.
A working definition: polish is making the app behave the way the user expects, even when the easy implementation behaves differently. None of the patterns below made the feature list. Most took an hour or two. Together they are what separates an app you delete after a week from one you keep on the dock.
Don’t cut where you can fade
Switching stations is the most frequent thing the user does, and the default implementation is a hard cut: stop the engine, tear down the connection, spin up a new one, resolve the playlist, buffer, play. The user hears audio, silence, audio — half a second of nothing on a fast network, more on a slow one. Every station change is a small punishment for changing your mind.
The naive optimisation is to make each step faster. It helps, but the silence never goes away — it just gets shorter. There is always a moment where the old stream is dead and the new one has not arrived, and the user lives inside that moment.
The polished move is not to shrink the gap but to overlap it. Wellenreiter runs two audio engines in parallel during a change. The old one keeps playing at full volume; the new one starts silently and connects in the background. Once it is actually producing audio, an equal-power curve ramps the old engine down and the new one up over about a second.

The shape matters. A linear cross-mix drops the perceived loudness by about 3 dB at the cross-over, because two uncorrelated signals do not add coherently. The cosine/sine pair keeps it flat — the same trick every DJ mixer uses.
private func applyRampVolumes(progress: Double) {
let old = cos(progress * .pi / 2) // 1 → 0
let new = sin(progress * .pi / 2) // 0 → 1
primary.engine.mainMixerNode.outputVolume = Float(old)
secondary?.engine.mainMixerNode.outputVolume = Float(new)
}The more interesting half is what happens when the new station does not connect — rotted URL, dead server, a network blink. The naive implementation has already torn down the old station, so a failure leaves the user with silence and an error dialog. The polished one changes nothing the user can see until the new audio is actually flowing. The active station, the LIVE pill, the track title, the lock-screen artwork all keep reflecting the station that is, in fact, still playing. The only hint is a small CONNECTING pill on the tapped row. If the connection succeeds the crossfade begins and the UI follows the audio; if it fails the pill quietly disappears. Failure becomes a non-event.
That leaves one question — when does the UI commit to the new station?
- When the user tapped. Too early; the connection might never come, and the UI is now lying.
- At the end of the ramp. Too late; the new audio already dominates while the pill and artwork still read as the old station.
- At the mid-point. Just right. The moment the new stream becomes louder than the old,
currentStationflips, the metadata observer switches engines, and the lock-screen info updates — all in a single SwiftUI tick. Audio leads, UI follows.
There is one bug that only surfaces after you ship this. For ~500 ms after the flip the old engine is still emitting events as it fades. Its ICY metadata keeps arriving, and without protection it would stamp the old station’s track title onto the new one — a crossfade-shaped state bleed. The fix is small: every audio event carries the identity of the engine it came from, and events whose engine no longer matches the current station are dropped.
private func handlePrimary(_ event: AudioPlayerEvent, from sender: ObjectIdentifier) {
// The primary slot outlives its station for ~500 ms after a mid-ramp
// flip. Drop late events so the new station doesn't inherit the old title.
guard sender == primary.id, primary.station == currentStation else { return }
apply(event)
}The pattern generalises beyond audio. Whenever two states have to replace each other — two screens, two contexts — let them overlap, commit when reality reports back, and roll the swap back without ceremony when it doesn’t. The cut is a worst case, not a default.
The contract beats the convention
Internet radio servers can embed the current song title in the audio stream, but only if you ask — one header line, Icy-MetaData: 1, on the request. Apple’s AVPlayer had a documented way to inject that header. On iOS 26 it silently stopped including it. No deprecation, no warning, no console output. Audio plays fine; titles never arrive, because the server was never asked. The bug is invisible unless you compare against the station’s own website.
The polished response is not “file a radar and wait” — the fix is nine months away in the next major OS. It is to name the contract the app actually depends on — track titles flow from the server into the app — and replace whatever platform piece is failing to honour it. Wellenreiter’s engine is no longer AVPlayer; it is a third-party Icecast client (dimitris-c/AudioStreaming) that controls every byte of the request and demuxes the metadata itself. Not free — there is plumbing I now own — but the feature no longer hangs off an API that broke its promise in silence.
The menu-bar app is the same lesson in a different place. SwiftUI offers MenuBarExtra, the obvious, conventional way to build a menu-bar app. But it cannot be opened programmatically, and the whole point of this app is a popover that springs open under a global hotkey (⌃⌥W). So the shell is not pure SwiftUI: it is an AppKit NSStatusItem driving an NSPopover, with the hotkey registered through Carbon’s RegisterEventHotKey — the SwiftUI view lives inside the popover, but the things SwiftUI cannot do are done by the frameworks that can. The convention was MenuBarExtra; the contract was open on a hotkey, and the contract won.
A contract is what the app promises the user. A convention is how you happened to build it. When they conflict, the contract wins.
Honor what the user meant, not what they tapped
There is one gesture on a station row: tap. But its meaning depends on context. Tap a station that is not playing — play this. Tap the one already playing — show me what is playing (the user already hears audio; they almost never mean start over). Tap a station you just tapped while it is still connecting — play this and take me to the player.
The lazy implementation treats every tap as play, so tapping the active station triggers a 1.5-second audible re-buffer and feels like the app didn’t believe you. Adding a real double-click gesture is worse: now every single tap waits a quarter-second to see if a second one is coming, and the 95% who never double-tap pay for the 5% who do. Wellenreiter reads the second tap in context instead: if it lands on the active station while it is still connecting, the app remembers the user wants the player and slides it in the moment audio starts — no recogniser, no latency, same behaviour whether you tap fast or slow.
The menu-bar popover applies the same respect to a different input. A menu-bar app lives under the cursor, but a good one never requires it: ⌃⌥W opens the popover with the search field already focused, arrow keys move through results, Return plays the selection and dismisses. You can switch stations without your hands leaving the keyboard.
The available gestures number a handful; the meanings the user wants to express number dozens. You bridge the gap with state and timing, not by inventing new gestures.
The engine is the source of truth
Wellenreiter’s “Recently played” tab can sort by most listened to, which needs an honest number of seconds. The naive count — play tapped to pause tapped, summed — is wrong in three invisible ways. Connection time is not listening time (a station can take five seconds to buffer). Network hiccups are not listening time (the engine refills its buffer mid-song). Pauses are certainly not listening time (Date() - sessionStart hands a station an hour of false credit while the user is away).
You can patch each with extra state, until the next edge case shows up. The polished move is to ask who already knows when audio is flowing: the engine does. It exposes a state machine — idle, buffering, playing, paused, failed — and playing is the only state where sound reaches the speaker. Open a stopwatch when the state enters playing, close it when it leaves. Every segment is honest by construction; connection, hiccup and pause all exit playing on their own. (One guard: the state flickers buffering → playing → buffering for ~200 ms while the audio unit settles, so segments under a second are discarded.)
The same reflex answers a different question — whether to record at all. When the user taps a station, the naive code writes “played this” to the recents list and then connects. If the stream is dead, the list now recommends things you tried to play. So the recents entry waits for the engine to confirm playback; failed streams leave no trace.

In any app with a state machine — playback, downloads, sync — questions of “how long” and “did this happen” belong to the engine’s states, not the UI events that triggered it. UI events are intent; engine state is reality. When they disagree, the engine is right.
Performance is felt, not measured
Users do not read profiler graphs. They feel two things: whether scrolling is smooth and whether taps respond. A stutter while flicking through 250 stations is not a millisecond budget — it is a vibe: this app is heavy.
When the app downloads a station logo, the JPEG bytes are decompressed into pixels lazily — not on load, but the first time the image is drawn. Scroll fast and a dozen fresh covers decode at once, on the very thread trying to keep the scroll smooth. The fix is to decode up front, on the background thread that already has the bytes, via UIImage.preparingForDisplay(), so it never ambushes the scroll. Two companions: keep a thumbnail-sized copy of each cover so a 1024×1024 logo is never composited into a 60×60 cell at scroll time, and recompute the alphabetical sort only when its inputs change, not every redraw. None of this is better in any way the user can point to — it just stops being subtly bad.
“Move it off the main thread” is half the answer. The other half is “and don’t run it again next frame for no reason.”
Clean the data you did not author
Internet radio metadata is a museum of horrors. Stations named __WACKENRADIO__, names that are 90% comma-separated genre tags, titles in all-caps with stray punctuation. Displaying the source verbatim looks lazy even when it is technically correct. Wellenreiter normalises every station name before showing it: underscores become spaces, clutter is stripped, whitespace collapses. __WACKENRADIO__ shows as WACKENRADIO and sorts under W. The cleaning happens silently, every time.
The same field that carries song titles — ICY StreamTitle — is also where stations push ads, jingles, station IDs, and “now playing on…” promos. Surface those as the live track and the track history fills with junk. So a small heuristic decides whether a StreamTitle actually names a song before it reaches the now-playing surfaces or the history. It is deliberately conservative — it rejects only on positive junk signals (URLs, the station’s own name, promo phrasing, a bare single-word ID) and keeps anything that plausibly reads as a title, because dropping a real song is worse than letting the odd promo slip through. That is why the menu-bar history in the screenshot above is all music and no station chatter.
Long titles get one more touch. A name like “Concerto for Violin and Orchestra in D major, K. 218, II. Andante cantabile — Anne-Sophie Mutter, Berliner Philharmoniker” would either wrap and make the layout jump every song, or truncate and lose information. Instead short titles sit centred under the artwork and long ones scroll gently, after a two-second pause so you can read the start.
Cleaning data at render time is a form of respect. It is what makes an app look finished rather than merely functional.
Remember what the user was doing
SwiftUI rebuilds aggressively, and every rebuild is a forgetting waiting to happen. The non-obvious case: when the mini-player slides in over the tab bar as audio starts, the tab bar’s container lays out again, and the default behaviour resets each tab’s navigation stack — so a user three screens deep in the SomaFM list gets bounced to the root the instant audio starts. Tap, listen, lose your place. The fix is to hold each tab’s NavigationPath in a parent object that lives outside the part of the hierarchy that rebuilds. Selected tab, scroll position, search query, expanded sections — each is a separate fix, invisible when it works and infuriating when it doesn’t.
Why bother
Reading these back, a few things recur. Polish is usually about removing, not adding — latency, forgetting, ceremony, the gap between intent and behaviour; a surprising amount of it makes the code shorter. The bug almost always lives in the gap between two systems — audio and network, view hierarchy and lifecycle, decoder and scroll engine. And the user has the simpler mental model; honour it — they are consistently right, and the easy implementation is consistently wrong. Most of these reproduce only on real hardware, on real networks, in the car — never in the simulator.
None of this is in the App Store description, and most users will never consciously notice a single pattern, because the point is that they don’t. Polish is the gap between “the app does the thing” and “the app does the thing the way I expected,” and that gap is where people decide whether the icon stays on the dock. The list is not closed — it never is. That is the actual job, most days. The feature list was the easy part.
Seventeen Characters: Designing VIN Entry for When You Cannot Scan
Scanning a barcode is the happy path. Point the camera, hear the beep, done. But in an automotive diagnostics app the camera is not always an option: the VIN sticker is peeled off, the car is on a lift in bad light, the value arrives over a diagnostic link and a human has to confirm it by hand — or there simply is no camera at all. Then you are back to the oldest interaction in computing: a person typing characters into a field.
This post is about one of those fields. Not a glamorous one — the Vehicle Identification Number. Seventeen characters of dense, error-prone, standardized nonsense. It turns out that “type 17 characters” hides a surprising amount of UX, and chasing it took me through three quite different designs, each one moving the rules of the domain a little deeper into the moment of input.
What makes a VIN nasty
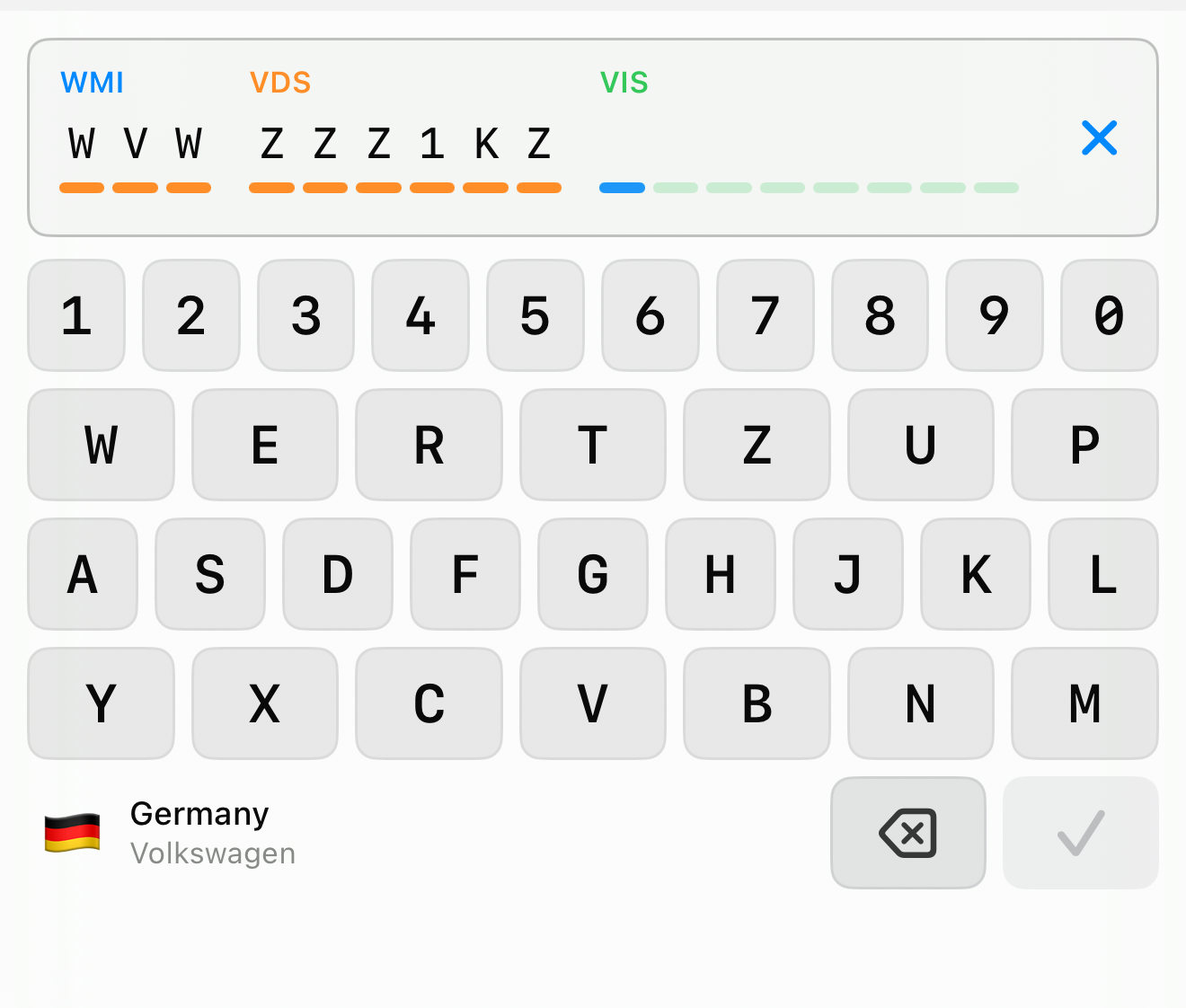
A VIN looks like free text and behaves like a protocol. ISO 3779 fixes the length at exactly 17 characters. ISO 3780 carves it into three sections: the WMI (positions 1–3, who built it), the VDS (positions 4–9, what it is), and the VIS (positions 10–17, which exact one). Position 9 is a check digit computed from all the others. The letters I, O and Q are forbidden, precisely because they are too easy to confuse with 1, 0 and 0.
So the value is not free text at all. It has hard syntax, a built-in integrity check, and a fixed shape. Every one of those facts is a chance to help the user — or, if you ignore them, a chance to let them fail silently.
Stage 0: the plain TextField
Here is the version you write in thirty seconds, the one that is mechanically correct and does nothing wrong by the compiler’s standards:
TextField("VIN", text: $vin)
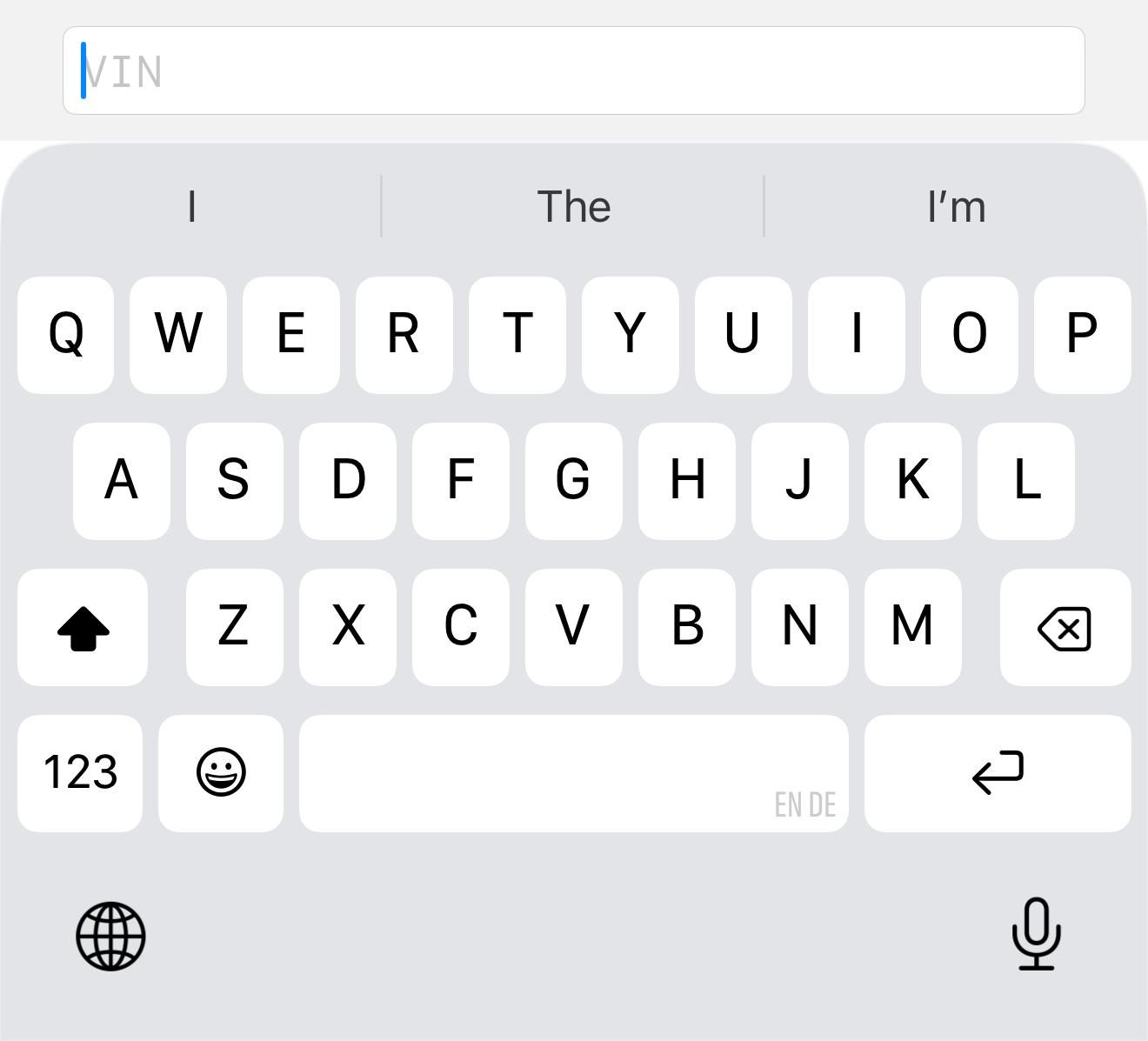
Count the ways this betrays the person using it. It offers autocapitalization and autocorrect, which mangle a VIN. It happily accepts I, O and Q. It accepts the 18th character without a word. It gives no hint that the value is 17 long, no sense of progress, no feedback that what was typed is even plausible. The user finds out it was wrong later, somewhere else, from an error that no longer points at the field. The field knew the rules and kept them to itself.
Stage 1: a field that understands VINs
The first real iteration moved the domain rules into the field. The same text input underneath, but now it normalizes to uppercase, strips I/O/Q and anything past 17 characters as you type, runs the ISO check-digit algorithm, and shows its understanding live: a status pill, a character count, and a breakdown into WMI / VDS / VIS with the detected model year.
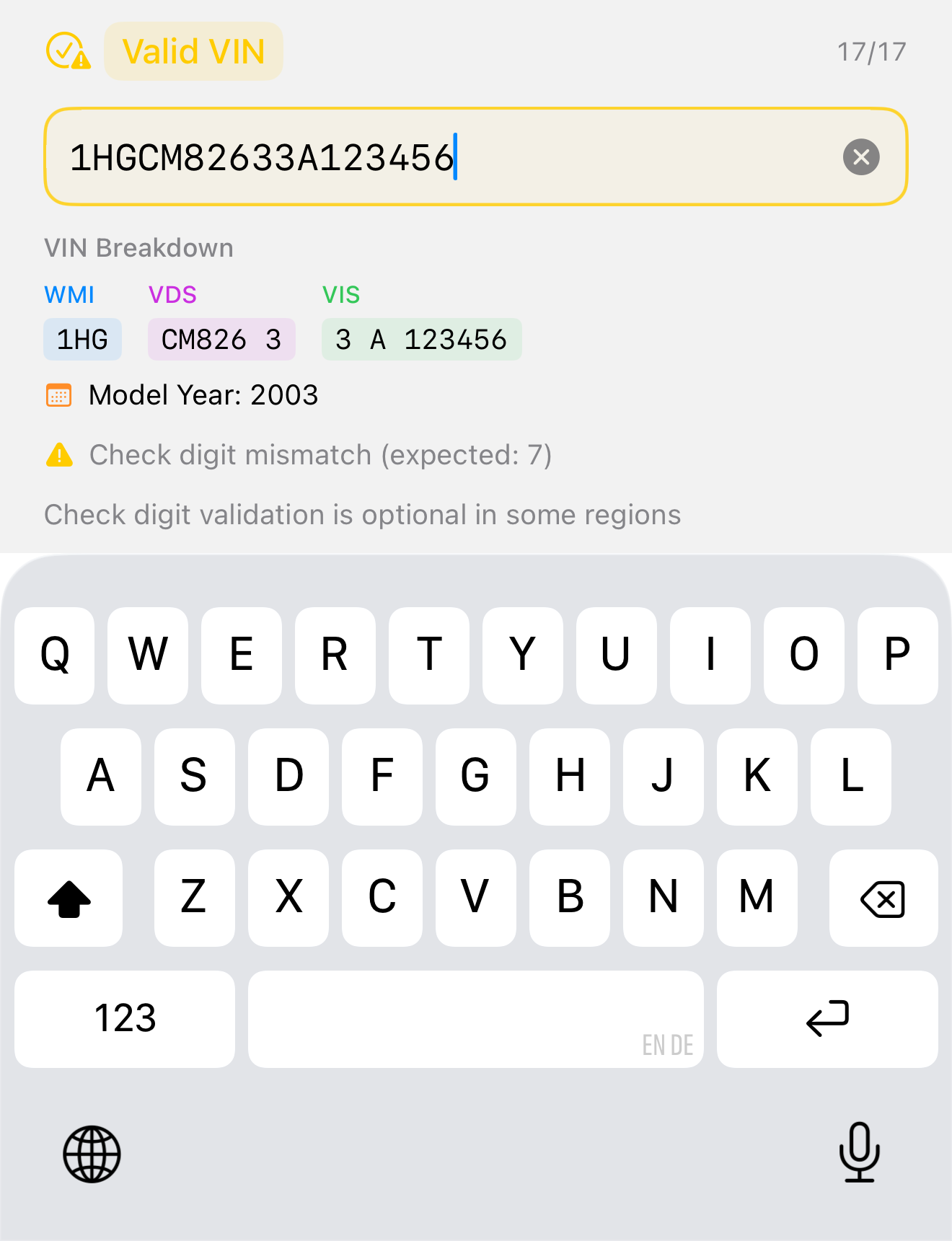
The important shift is not the parsing — it is the timing. The field tells you what it thinks while you type, not after you submit. When the check digit does not match it is surfaced as a gentle warning rather than a hard rejection, because outside North America the check digit is genuinely optional and a false “this is wrong” is worse than no opinion. When the input is malformed, the field says so, in place, immediately:
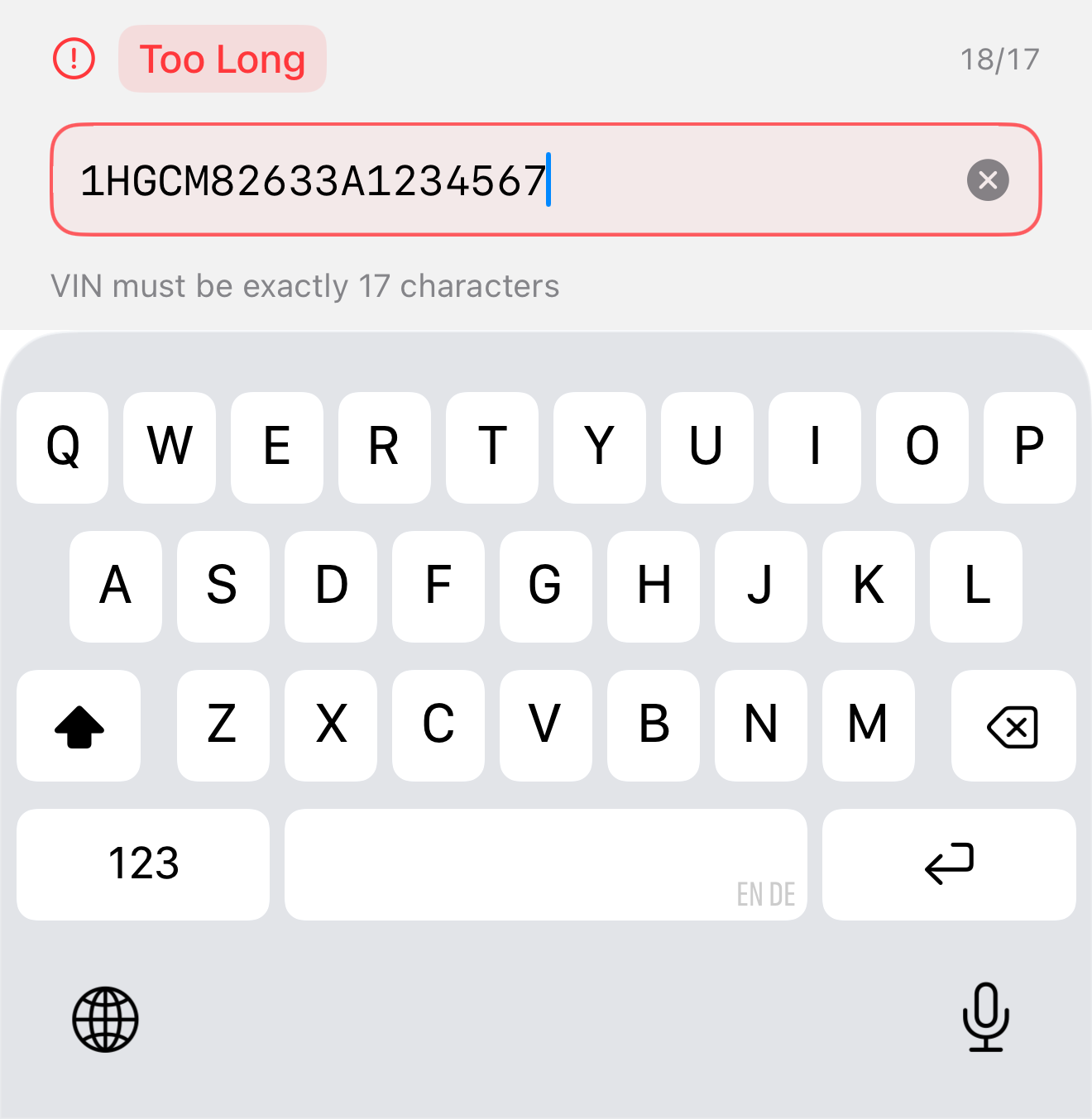
This is already a good control. For many apps it is the right answer, and it is the one I would still reach for inside a Form. But it inherits the system keyboard, and the system keyboard does not believe in our rules. It shows the letters I, O and Q. It shows punctuation that can never be valid. On a small screen, in a workshop, with gloves on, the keyboard fights the field.
Stage 2: a keyboard that only speaks VIN
The last iteration asked an uncomfortable question: if the input is a small domain-specific protocol, why are we using a general-purpose keyboard at all?
So the keyboard became part of the control. VINKeyboardInput ships its own keypad. It is laid out QWERTZ or QWERTY so the keys sit where a touch-typist expects them — but it simply has no I, O or Q keys, because those characters can never be valid. There is nothing to reject because there is nothing invalid to press.
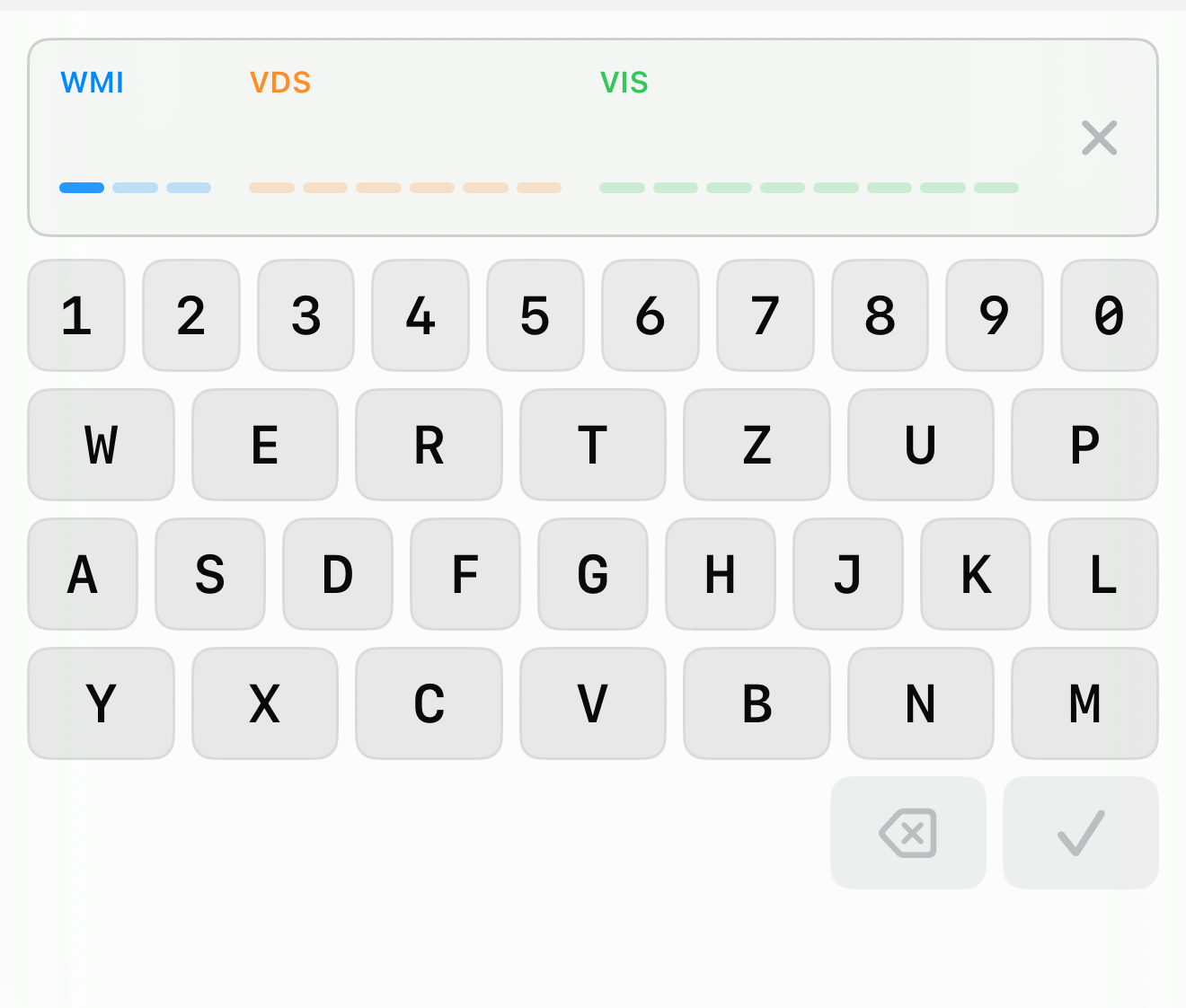
The display is no longer a line of text — it is seventeen fixed slots, grouped and tinted by section (WMI blue, VDS orange, VIS green). Every character you type lands directly on its slot, so the structure is visible as you type, not reconstructed afterwards. The next slot to be filled pulses quietly, so there is always an answer to “where am I?”.
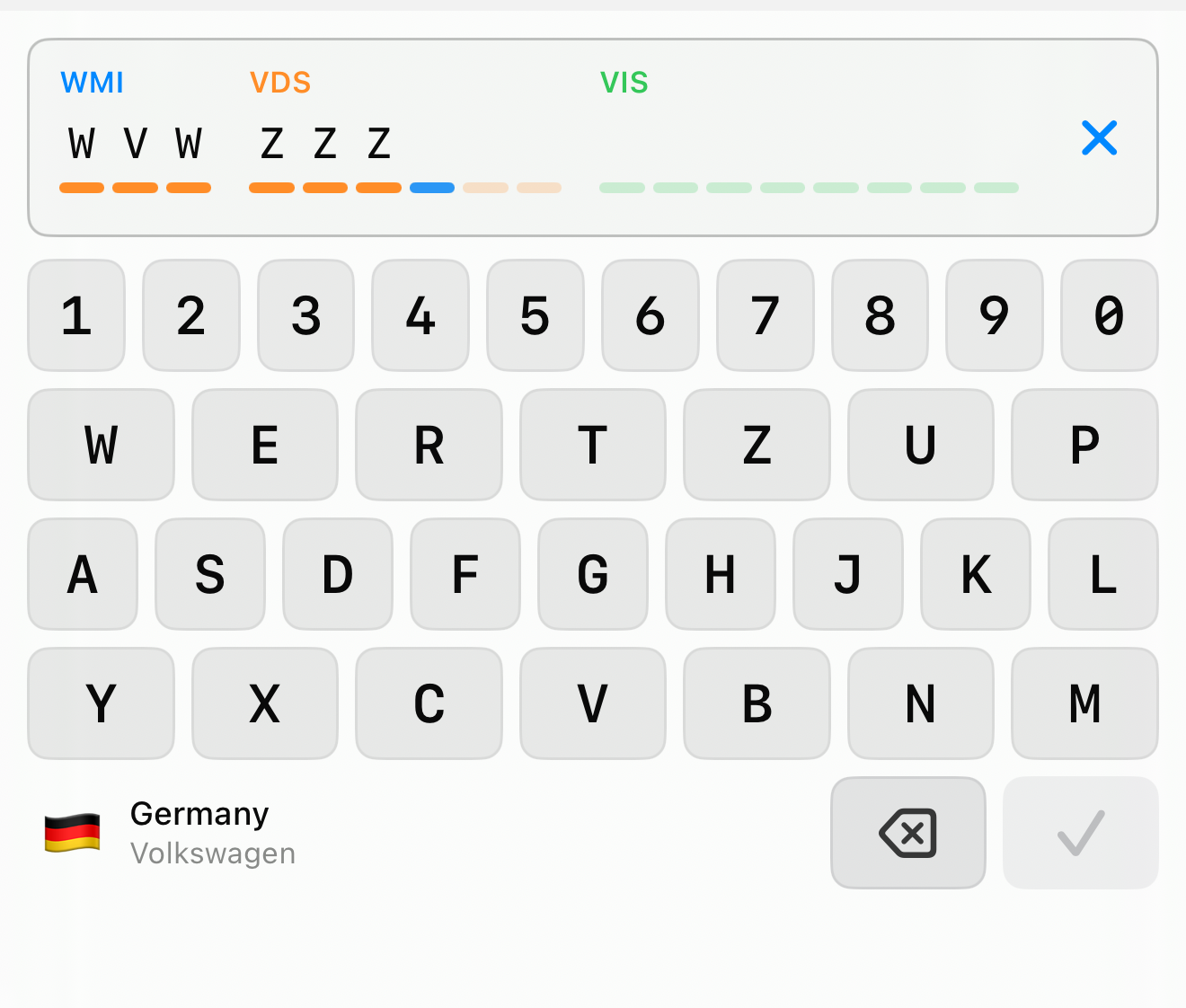
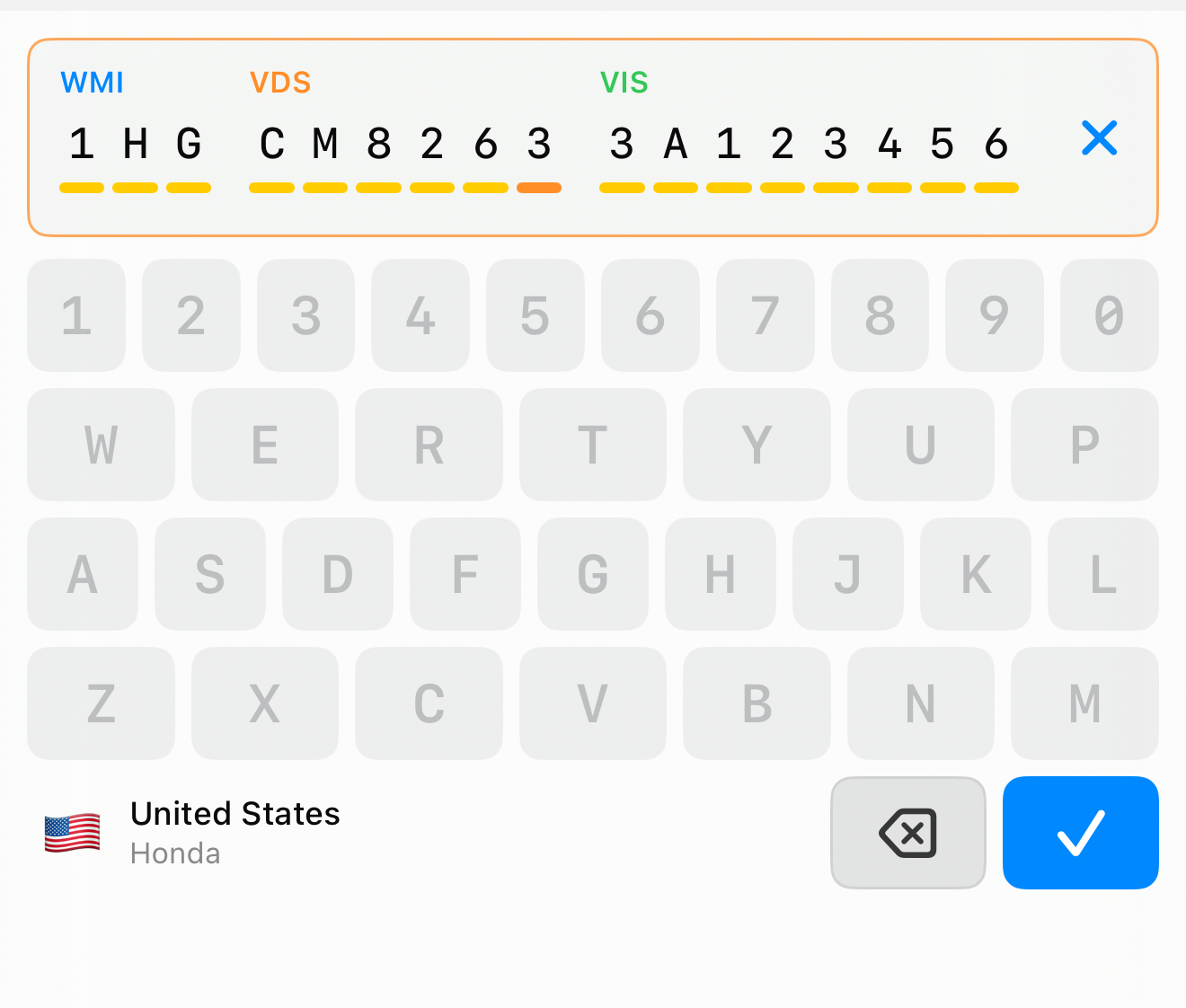
The control also moves position-specific rules onto the keys. When you reach position 9 — the check digit — the keyboard knows that only digits and the letter X are legal there, and everything else dims out. You cannot type an invalid check digit because, for that one keystroke, the invalid keys are gone.
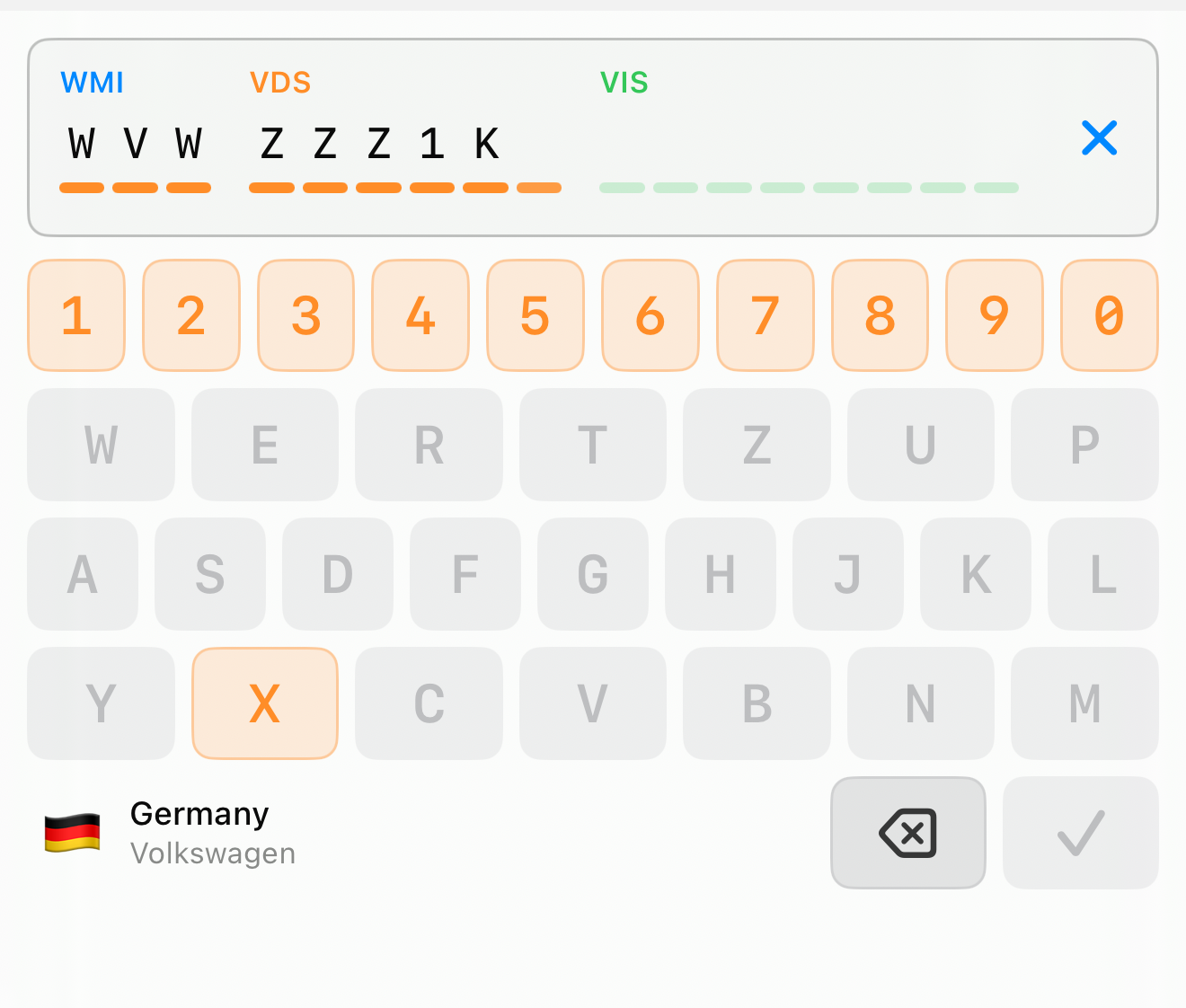
And because the first three characters already identify the manufacturer and its country of origin — that is exactly what the WMI is — the keyboard can show you who and where, live, the moment those characters exist. A flag, the country, the manufacturer, derived entirely from the standardized WMI tables. It is a tiny thing, but it turns blind data entry into something you can sanity-check with your eyes: yes, that is a German Volkswagen, that looks right.
When all seventeen slots are full and the check digit agrees, the submit key lights up and every other key goes quiet. The control has guided the entry from the first keystroke to a value it is confident in.
When is this worth it?
Building a bespoke keyboard is not free, and most text inputs should never get one. The plain field is the right default; reaching past it needs a reason. The rule of thumb I settled on: build a domain control when at least two of these are true.
- The input has hard syntax rules.
- Mistakes are expensive, common, or disruptive.
- Users enter this kind of value repeatedly.
- The displayed form differs from the stored value.
- There is a natural keypad, grouping, or action layout.
- Validity directly gates an action — Send, Connect, Save.
A VIN ticks almost all of them, which is why it was worth three iterations. The same reasoning applies to a whole family of inputs in the automotive and diagnostics apps I work on: CAN identifiers, UDS service payloads, IP and MAC addresses, BLE UUIDs. None of them are free text. All of them deserve a control that knows it.
The thread through all three
The progression from a plain field to a domain keyboard is really one idea applied harder and harder: move the rules of the domain into the moment of input. The plain field knows nothing and tells you nothing. The smart field knows the rules and explains itself. The keyboard goes furthest — it makes the invalid states unreachable, so there is less to validate because there was less that could go wrong.
That is the same promise as the scanner, just without a camera. You are still asking the user to trust that the app is doing the right thing. The difference is that here, instead of trusting a recognizer, they can watch the structure assemble itself, character by character, and see that it is right.
All three controls live in CornucopiaSUI, the SwiftUI half of the Cornucopia toolbox, and ship in CarLab.
Letting an agent talk to my ECUs
Something has changed for me at the bench in the last few weeks, and I want to write it down before it stops feeling new.
I have spent the last decade building or using diagnostic tools that put a human between the agent of investigation and the bus. CANcorder, Swift-CANyonero, my Linux toolbox — mcandump, mcangen, canconf — countless one-off scripts. The idea was always the same: give the human a clear view of what the bus is doing, and let them ask the next question. The next question is the interesting part.
Generative AI has been around the bench for a while too, but mostly as a thing that read my logs after the fact. Help me decode this byte. Help me write this DBC. Help me understand why an ECU answers 7F 22 33. That is useful, and I do not want to talk it down. But it is post-mortem work — the agent is staring at a frozen photo of a session that already ended.
What I wanted, and never quite got, was an agent that sat at the bench with me. One that could send a frame, watch what came back, decide what to ask next, and tell me what it learned in the same loop where I am thinking. Not a replacement for me. A colleague.
The thing that has changed is that this is now real. I built a small piece, plugged a Scania S8 truck into it, and asked an agent to find the VIN. It did. From inside a chat box.
I am still a little stunned by how good that feels.
Why a shell is the wrong boundary
Watching an LLM drive candump and cansend through a shell, parsing hex out of a scrolling terminal, is an exercise in watching a smart system spend its energy on the wrong layer. Every CAN frame becomes a string. Every reply becomes a regex. Every multi-frame ISO-TP transfer becomes process orchestration. The agent burns most of its context window on plumbing and gets the timing wrong anyway, because by the time stdout is parsed the next frame has already arrived.
The right boundary is structured. Frames are already structured: ID, flags, DLC, payload, timestamp. ECUs already speak request/response. Filters are already a feature of the kernel. The only thing missing is a server in the middle that knows SocketCAN well enough to do the right thing on each side and present the agent with a typed RPC.
Anthropic’s MCP is exactly that shape. The agent calls a typed tool, the server does the work, the agent gets a typed result. JSON in, JSON out, no shell in between. Once I tried it for one CAN tool, I could not stop wanting it for the rest.

mcanbus
The library came first.
I had two existing tools — mcandump and mcangen — that both reimplemented SocketCAN from scratch using raw libc. That was a deliberate choice at the time: the existing socketcan crate on crates.io is fine, but it pulls in optional async runtimes and abstracts the kernel a little further than I wanted for tools that move millions of frames per second. Hand-rolling raw socket code twice gives you an itch though. Both tools shared the same CAN_RAW open sequence, the same recvmmsg/sendmmsg patterns, the same cmsg walk for SO_TIMESTAMPING, the same netlink dance for RTM_NEWLINK and IFLA_CAN_STATE. I kept editing two copies of essentially the same code.
The MCP server gave me a real reason to factor that out. The result is mcanbus — a SocketCAN crate that stays close to the kernel:
FrameisCopy. Fixed 64-byte data buffer plus a length tag. Wastes 56 bytes for classic 8-byte frames; the simplicity it buys — no lifetimes, trivial fan-out, batch arrays — is worth more than the bytes are.Socket::openexposes every knob that mattered to me on the bench: FD frames, error filter, timestamping mode (hardware → software → none),SO_RCVBUF/SO_SNDBUF, RX timeout,O_NONBLOCK,CAN_RAW_FILTER. Defaults are pragmatic — hardware timestamping requested, 8 MiB RX buffer, 500 ms read timeout, FD on.recv_batchandsend_batchuserecvmmsg/sendmmsgfor high-throughput pipelines. EINTR is hidden, EAGAIN is hidden — both surface asOk(None)so the caller’s stop-flag pattern just works.- A
Readerhelper, gated behind a default-onreaderfeature, fans frames out to multiple subscribers viacrossbeam-channel. One RX thread, N consumers, per-subscriber drop counters, lock-snapshot fan-out so subscribe and unsubscribe never block the reader.
That last bit was my litmus test. If a SocketCAN crate cannot survive eight subscribers fanning out a saturated bus without losing a frame, it is not the crate I want. This one survives it without breaking sweat: validated against real hardware at 5000 fps for three seconds, every subscriber saw exactly the same 15 028 frames, no drops, all queues drained at exit.
There is also netlink. Interface::set_up, set_down, cycle, state. The cycle call is the BUS-OFF recipe for gs_usb-class adapters: bring it down, sleep 150 ms, bring it back up, because the kernel will not restart these devices on its own. That code lived in mcangen’s main file; pulling it into the library means anyone touching gs_usb hardware gets it for free.
socketcan-mcp
The server itself is small. About 500 lines of Rust on top of rmcp — Anthropic’s own Rust SDK for MCP, which has reached the point where you declare a struct, decorate methods with #[tool(description = "...")], and the schema generation, RPC routing, and stdio transport are taken care of for you.
Five tools to start:
| Tool | What it does |
|---|---|
list_interfaces | Enumerate every CAN-class interface with state and bitrate. |
iface_state | Detailed status (up/down, controller state, bitrate) for one interface. |
capture | Listen for up to N ms and return up to M matching frames. |
send_frame | Transmit a single frame. |
send_and_capture | Transmit and immediately capture replies in the same call. |
All write tools are gated by an environment-variable allowlist. Setting SOCKETCAN_MCP_INTERFACES=can0,vcan0 is the only way to permit sends; an empty allowlist is the safe default. SOCKETCAN_MCP_READONLY=1 reduces the surface to the read-only tools regardless of allowlist. There is no config file, no hidden state, no surprises. The server has no global mutable state of its own — every tool call opens its own sockets and tears them down.
The Scania moment
This is the part I want to remember.
I have a Scania S8 — the R-series cab, KWP2000 over ISO-15765 extended addressing — connected to my bench through two USB-CAN adapters wired to the same physical bus. Diagnostic side, not powertrain. I wanted a test that was not synthetic: a real ECU, real protocol, real timing. So I plugged the truck in, sat down at my editor, and asked the agent to find the VIN.
The first attempt was deliberately the hard way. The MCP server at that point had only the five tools above. No ISO-TP. The agent had to do the segmentation and flow control by hand.
It opened with a recon capture. Listened to can0 for a couple of seconds, saw the bus shape, decided which IDs to use. Then sent the standard KWP request — service 0x1A, local identifier 0x90, ISO-TP single frame on 0x18DA00F9 (tester 0xF9 to target 0x00):
TX 18DA00F9 02 1A 90 CC CC CC CC CCThe ECU answered with a First Frame on 0x18DAF900:
RX 18DAF900 10 13 5A 90 59 53 32 52Twenty-four bits of decoding work for the agent. The PCI nibble 1 says First Frame. The next 12 bits 0x013 say total length 19 bytes. The first two payload bytes are the KWP positive-response header: 5A is service 1A echoed with the high bit set, 90 is the local-identifier echo. The remaining four bytes are the first piece of the VIN: Y S 2 R.
YS2 is Scania’s manufacturer prefix.
The agent sent the Flow Control by hand:
TX 18DA00F9 30 00 00 CC CC CC CC CCTwo consecutive frames came back:
RX 18DAF900 21 36 58 34 30 30 30 35 "6X40005"
RX 18DAF900 22 34 31 32 37 33 35 00 "412735"Reassembly is trivial once you have the frames. The agent put them together: YS2R6X40005412735. Seventeen characters. Valid Scania VIN. R-series cab, 6×4 drive configuration, the rest is plant code, model year, serial.
That entire session — recon, send, decode, flow control, reassemble — happened in maybe thirty seconds of agent time. Four MCP calls. No shell, no candump, no regex, no race conditions. The agent decoded the FF length field correctly, knew it had to send Flow Control, knew the KWP positive-response header, formatted the bytes back as ASCII when I asked.

isotp_request
After that worked, the obvious next step was to give the agent ISO-TP as a primitive. Four MCP calls is fine for a demo; it is not what you want when the agent is in a tight diagnostic loop with twenty different ECUs.
So mcanbus got an isotp module. Synchronous request/response, automatic Single Frame / First Frame / Consecutive Frame segmentation, Flow Control in both directions, ECU-side BS=0 supported, BS>0 returns Unsupported for now. Twelve unit tests for the encoding edge cases including the exact byte sequences I had just observed on the Scania bus.
The MCP server got a sixth tool, isotp_request. Same VIN read, one call:
{
"name": "isotp_request",
"arguments": {
"iface": "can0",
"tx_id": "18DA00F9",
"rx_id": "18DAF900",
"extended": true,
"payload": "1A90"
}
}Response:
{
"duration_ms": 1,
"response": {
"len": 19,
"hex": "5A905953325236583430303035343132373335",
"ascii": "Z.YS2R6X40005412735"
}
}One call, one millisecond. The library handles the segmentation, the agent gets the reassembled payload back. The leading Z. in the ASCII column is just the KWP header rendered verbatim — 0x5A is Z, 0x90 is non-printable.
That is the shape I want for diagnostic work from now on.
What this changes
The thing I keep coming back to is that the agent is not a nicer terminal. It is a colleague who reads everything I send back, remembers what we tried, notices patterns, suggests the next request. Every time the bench gets a new structured tool, that colleague gets sharper. Every time I make them parse candump output, that colleague gets stupider.
A short list of what I now do from inside a chat that I used to do from a shell:
- List the CAN interfaces and tell me which ones are healthy. →
list_interfacesreturns state and bitrate; the agent flags anything that is bus-off. - Capture five seconds on can1 and show me the IDs by frequency. →
capturereturns a structured list; the agent buckets and ranks them. - Send
02 10 03on can0 and show me what comes back in the next 200 ms. →send_and_capturedoes it; the agent annotates the response. - Read the VIN. →
isotp_requestdoes it; the agent decodes the KWP header and gives me the seventeen characters.
None of this replaces CANcorder for live inspection or Swift-CANyonero for building deep diagnostic stacks. It replaces the tmux window where I used to type four-letter commands at three in the morning when something unexpected was hiding on a bus. That window is the one that matters for exploratory work, and it now has someone in it who can read.
The pieces
Both crates are MIT-licensed, on GitHub, and on crates.io:
mcanbus— the SocketCAN crate. Pure libc, no async, optional zero-loss multi-consumer fan-out reader, ISO-TP request/response, netlink helpers.socketcan-mcp— the MCP server. Six tools, environment-variable sandbox, stdio transport, drops into Claude Desktop or Claude Code with a five-line config.
mcandump and mcangen will migrate onto mcanbus in a follow-up — same wire-level behaviour, less duplicated code. That part is paperwork.
The deeper work is on the agent side. Once I had a reliable structured channel between an agent and a CAN bus, more uses surfaced than I had originally drafted as tools. Long-running capture sessions backed by the fan-out reader. ISO-TP servers, not just clients, so the agent can imitate an ECU. DBC decoding, so frames come back as named signals. A first-class CAN-FD ISO-TP path. None of those are hard; all of them are clearly worth building now, where before they would have been bench scripts I never quite finished.
Closing the loop
The thing I underestimated is how much fun this is. For years the bench was a place where I read frames, decided what to ask next, sent the request, read the response — all in my head, with my fingers, in a terminal. None of those steps were hard. They were just mine. Closing that loop with a colleague who can read and decide alongside me has changed the texture of the work in a way I did not see coming. The bench is suddenly conversational, and the conversation is about the actual problem, not about the formatting.
I am, at the same time, both fascinated and a little uneasy at how fast this wheel is turning. mcanbus and socketcan-mcp together took a long weekend. Two years ago I would have called the same thing science fiction. Five years ago I would have called it impossible. The shape of “structured tool-calling between a language model and a real piece of hardware” is barely a year old, and it is already production-shaped enough to read a VIN off a Scania ECU in a millisecond. Whatever bench work I will be doing two years from now almost certainly does not exist yet today, and that is exhilarating and slightly disorienting in roughly equal measure.
CANsole is my forthcoming inspection-and-decoder side of the same toolchain — a desktop CAN debugger and simulator for working engineers who need to look at a bus, log it, decode transport protocols, and understand what an ECU is actually doing.
The Linux side, now, has a colleague.
Swift beyond Apple, five and a half years later
In October 2020 I wrote that I had decided to go all-in on Swift. Not just on iOS and macOS, where Swift obviously belongs, but pretty much everywhere: servers, command-line tools, reusable frameworks, UNIX-like systems, perhaps one day even the kind of embedded-ish tooling that had followed me around since the OpenMoko days.
Five and a half years later, I no longer think that was the right default.
This is a slightly longer post. Bear with me — I have been carrying this around for a while, and I wanted to think it through properly before writing it down.
TLDR: I still like Swift as a language. I no longer trust Swift as a general-purpose, non-Apple platform strategy.
That distinction matters. This is not one of those melodramatic “language X is dead” posts. Swift is very much alive where Apple needs it to be alive. It is productive, expressive, type-safe, and still one of the nicest ways to build software for Apple’s platforms. I have shipped Swift code, I will continue to ship Swift code, and for many iOS/macOS jobs it remains the obvious choice.
But the dream I had in 2020 was larger than that. I wanted Swift to become my one language for both sides of the wire. Client and server. GUI and daemon. App and tool. Shared model code, shared protocol code, shared transport abstractions. Less duplication, fewer mental context switches, more reuse.
I still want that kind of reuse. I just no longer think Swift is the best way to get it outside Apple’s platforms.

What I expected
Back then, Swift felt like it had finally crossed a threshold. Swift 5 had stabilized the ABI on Apple platforms. Swift Package Manager was usable. Server-side Swift had real momentum. The language community felt lively. Concurrency was on the horizon. The open-source story looked credible enough to believe that Swift could grow beyond its birthplace.
And there was a very personal reason why this mattered to me: I hate repeating myself. I have spent too much of my life building the same abstractions three times because one platform wanted Objective-C, another wanted Python, and the little box in the corner only tolerated C or C++.
Swift seemed to offer a way out. A modern language with value types, generics, protocols, closures, good tooling, and enough C interoperability to talk to the real world. The idea of writing one transport layer, one diagnostics model, one stream abstraction, and using it across desktop tools, mobile apps, and backend services was extremely tempting.
For a while, I really tried.
What actually happened
On Apple platforms, Swift got better. Outside them, it never quite became boring.
And boring is what I want from infrastructure.
When I build a product, the language and build system should be the least interesting part of the day. I do not want to wonder whether the Linux toolchain is lagging behind, whether Foundation behaves the same way, whether some package assumes Darwin by accident, whether deployment will pull in just the right runtime pieces, or whether the thing that worked last month will suddenly require spelunking through build flags, linker issues, or package manager corner cases.
Yes, all ecosystems have friction. Rust has friction. C++ has historic friction. TypeScript has the whole node_modules universe attached to its ankle. Python packaging can still make grown adults stare silently into the middle distance.
But those ecosystems are at least centered around the platforms where I use them. Rust is at home on Linux. TypeScript is at home on the web. C++ does not depend on one vendor’s platform priorities.
With Swift outside Apple, I kept having to account for the fact that these targets are not what the ecosystem optimizes for first.
Open source is not the same as independence
In 2020 I wrote, enthusiastically, that Swift being open source was the number one feature that had always irritated me with Objective-C.
I still think open source matters. But I also learned, or perhaps relearned, that an open repository is not the same thing as an independent ecosystem.
Swift may be open source, but Apple still sets most of the practical priorities: the language direction, the release rhythm, the documentation focus, the tooling, the flagship frameworks, the developer mindshare, and the commercial incentives. That is not a moral failing. It is perfectly rational. Apple created Swift to serve Apple’s needs.
The problem starts when I build non-Apple products on top of that assumption and pretend it is neutral infrastructure.
If a language is effectively owned by one platform vendor, then depending on it outside that platform becomes a business decision, not just a technical one. Will it still work? Probably. Will someone fix the rough edges that matter to my Linux daemon, Windows desktop helper, CAN tool, or server process with the same urgency as a problem that affects Xcode and iOS? That is a very different question.
For hobby projects, this is tolerable. For products, it becomes part of the risk calculation, and I have become much less willing to accept that risk.
The momentum problem
The other thing that faded was the feeling of momentum.
In 2020, Server-side Swift felt like a movement. Vapor, SwiftNIO, package libraries, community energy, people trying to prove that Swift could be more than “the new Apple app language”. It was fun to watch, and even more fun to participate in.
Today, from my corner of the world, it feels much quieter. Not gone. Not useless. But no longer something I expect to become the default outside Apple’s platforms.
When you choose a platform for long-lived software, you want the boring confidence that the ecosystem will be larger next year, the tooling smoother, the weird bugs rarer, the deployment story more standardized, the hiring pool less exotic, the dependency graph healthier.
With Swift outside Apple, I mostly feel the opposite now: more caveats to check before the actual product work can begin.
Some of it is technical. Some of it is social. Some of it is simply that the rest of the world moved on. Rust became the obvious answer for a lot of systems work. TypeScript won the UI tooling war by being everywhere. Python remains annoyingly useful. Modern C++ is, much to my younger self’s surprise, pretty good again in the places where C used to be the only realistic answer.
That does not make Swift a bad language. It just means it stopped being the obvious answer for the work I do outside Apple’s platforms.
What replaced it
My recent projects tell the story better than a theoretical argument.
When I migrated this website away from Lektor, I moved to Zola. Not because I wanted to join a Rust fan club, but because a single binary static site generator with no Python runtime, no virtualenv, and builds under a second is exactly the kind of boring I like.
When CANcorder grew into a serious desktop application for macOS, Windows, and Linux, I did not reach for Swift. I used Tauri: TypeScript and React for the UI, Rust for the backend, and a native shell around it. That stack has its own tradeoffs, as the two-million-CAN-frame table happily reminded me, but the deployment target and the ecosystem match the job.
When I returned to MCU work on the ESP32, I went back to C++. I did not expect to enjoy that sentence, but modern C++ is no longer the language I left behind two decades ago. Type inference, move semantics, coroutines, ranges, and decent embedded toolchains make it a perfectly reasonable choice for FreeRTOS abstractions and hardware-adjacent code.
When I need quick automation, glue, importers, converters, and diagnostic helpers, Python still earns its keep. It is not my favorite language in the abstract, but it is often the fastest way to get from problem to solved problem.
And on the web, TypeScript is simply there. The libraries, the tooling, the debugging story, the browser APIs, the hiring market, the amount of production use — all of it points in the same direction. I may grumble about the ecosystem, but I do not have to explain why I chose it.
That is the pattern now:
- Mobile and Apple-native apps: Swift, SwiftUI where it fits, UIKit/AppKit where it must.
- Desktop products: TypeScript/React plus Rust via Tauri.
- Systems and performance-sensitive backend pieces: Rust.
- Embedded and RTOS work: modern C++.
- Glue, tooling, and quick data work: Python.
It gives me more stacks to keep in my head, but fewer fights with the wrong tool.
A data point from this month
While I was writing this, I decided to stress-test the argument with my own hands. I took a Swift project of mine — a small NAT-traversal broker for automotive diagnostic sessions, around 750 lines of state machine and socket plumbing — and rewrote it in Rust. Same REST contract, same wire format, same behaviour. Two afternoons, with AI doing most of the typing.
That part is worth mentioning, too: AI agents seem to have a surprisingly good time writing Rust. The compiler gives them a tight feedback loop, the ecosystem is explicit, and the resulting patches are often easier to review than the same amount of concurrency-heavy Swift. For the kind of focused porting work I do more and more these days, that is very helpful.
I was not chasing performance. I wanted the maintenance surface to feel less precarious: no Foundation-on-Linux quirks, no third-party socket fork on a noTLS branch, no swift-server runtime to babysit inside a 200 MB Docker image. A tiny stripped binary in a small runtime image was, frankly, the headline feature.
But I also built a small benchmark on top of both versions, just to know, and ran it on the same machine, same loopback, same client. After correcting the benchmark harness to count bytes actually delivered to the receiving side, the numbers became less theatrical, but still pointed in the same direction.
| Concurrent sessions | Swift broker | Rust broker |
|---|---|---|
| 1 | 1,571 MiB/s | 2,989 MiB/s |
| 4 | 1,104 MiB/s | 2,039 MiB/s |
| 16 | 1,664 MiB/s | 1,827 MiB/s |
| 64 | 1,304 MiB/s | 1,544 MiB/s |
All rows passed wire verification in both directions. The Swift broker also allocated all 64 sessions in this rerun, so the earlier “0/64 sessions” result was too strong. What did remain was the lifecycle problem: after every default-logging run in this sweep, the Swift broker process exited with SIGPIPE and no useful application-level log. The Rust broker stayed up until explicitly stopped.
The throughput delta is therefore not the main story. Yes, Rust was faster across the sweep, from about 1.1× at sixteen sessions to about 1.9× for a single session. But what unsettled me more was still the disappearance after the benchmark: no stack trace, no clean shutdown path, just a missing PID after the client finished. The most likely culprit remains teardown around the thread-per-connection forwarding model — exactly the kind of failure mode I do not want in a small broker daemon.
In production, that kind of lifecycle fragility is a reconnect-storm hazard. If the broker restarts while devices are connected, all of them will try to reallocate at the same moment. The Swift implementation could push bytes, but it did not give me the operational confidence I wanted. The Rust port, with one tokio task per slot and no per-chunk locking, survived the same tests without drama.
I did not start this rewrite to prove a point about Swift. The result made the original argument much harder to ignore.
Where Swift still wins
To be clear, I am not moving away from Swift where Swift is the native language of the platform.
For iOS, iPadOS, watchOS, and visionOS, Swift remains the default answer. On macOS, it still makes sense when the project is an Apple-native app or a companion to the mobile side. Recent work on RetroPlayer and the CANcorder iPhone companion app made that obvious again. Even when SwiftUI hit its performance ceiling and I had to go back to UIKit and hand-drawn cells for fluid scrolling, Swift itself was not the problem. The language did its job. The framework abstraction was the thing that needed a shorter leash.
That is an important distinction. My disillusionment is not with Swift as syntax, semantics, or type system. I still enjoy writing it. I still like protocols with default implementations, enums with associated values, value semantics, structured concurrency, and the general feeling that many errors are caught before they escape into runtime.
The part I no longer trust is the platform promise.
Swift is a great Apple language. It may even be the best Apple language we have ever had. But I no longer believe it is the language I should bet my non-Apple products on.
It is also no longer my default for non-mobile products just because they could be written in Swift. Desktop tools, servers, CLIs, cross-platform products, and hardware-adjacent utilities now have to earn their stack on their own terms.
Signs of life, watched from a distance
Two corners of the non-Apple Swift world have started to feel less stagnant lately, and it would be dishonest not to mention them.
There is now an official Swift on Android working group, with a real toolchain effort and proper coordination instead of heroic individuals reinventing the wheel each year. If it sticks, the prospect of sharing model and protocol code between iOS and Android Swift becomes plausible rather than theoretical.
SwiftWasm is the other one. After a long stretch as a side project, it has fresh momentum and a credible path toward upstream integration. Compiling Swift down to small .wasm modules that run in browsers and WASI runtimes is exactly the kind of cross-platform story that justifies the language choice — and it would directly attack the “write everything twice in TypeScript” problem I have been quietly accumulating frustration over.
Both efforts could change the calculation again. I want them to.
But I am watching from a distance. Until either of them feels boringly reliable, I cannot base product decisions on them.
The cost of almost portable
What has cost me time in practice is the last ten percent of portability.
If a technology clearly does not support a target, you move on. No drama. The decision is made for you. But if it mostly supports the target, you can spend years discovering the missing pieces only after the easy parts are done.
The demo works. The README says Linux. The package builds. The server starts. The CLI runs. Then the real product begins, and suddenly the paper cuts matter: missing APIs, platform-specific assumptions, packaging wrinkles, CI oddities, unfamiliar deployment paths, fewer examples, smaller community, less operational folklore.
None of these are fatal on their own. You can work through them, but they keep taking time away from the work the language choice was supposed to simplify.
I have enough complexity already. Automotive diagnostics, Bluetooth, USB drivers, CAN adapters, ISO-TP reassembly, UI performance, cross-platform desktop packaging — these things bring their own trouble. I do not need the programming language to add another layer of “almost”.

Conclusion
If 2020 was the year I allowed myself to believe in Swift everywhere, 2026 is the year I am putting the boundary back.
Swift for mobile and Apple-native apps: yes.
Swift as the foundation for all my non-mobile work: no.
That may sound like a retreat, but for me it is mostly a correction. The Apple parts stay in Swift. The other parts no longer get Swift by default.
I still want reusable solutions. I still want fewer duplicated abstractions. I still want clear, type-safe, maintainable code. I have just stopped insisting that one language must provide all of that everywhere.
In 2020, going all-in on Swift felt like the right bet.
In 2026, I am limiting that bet to the platforms where Swift is clearly at home.
Reverse engineering a USB device driver on macOS
I have been writing a macOS userspace driver for a CAN bus adapter. The device uses a custom USB protocol — bulk endpoints, vendor control transfers, a command language with opcodes and terminators. The Linux kernel has an open-source driver for the same hardware, so porting it should have been straightforward. I read the kernel source, mapped the protocol structures, implemented the init sequence in Rust, and… nothing. The device’s status LED stayed dark. No frames received.
The closed-source macOS driver from the vendor, on the other hand, worked perfectly. Plug in, initialize, green LED, frames flowing. Same device, same bus, same cable.
Obviously the vendor’s driver was doing something different. But what?
The state of USB tracing on macOS
On Linux, you would fire up Wireshark with usbmon, or cat /sys/kernel/debug/usb/usbmon, and have a complete packet-level trace within seconds. On Windows, there is USBPcap. On macOS, there is… nothing comparable.
Let me be specific about the options I considered:
Hardware USB analyzers. The gold standard. A device like a Total Phase Beagle or an Ellisys sits between the host and the device and captures every transaction at the electrical level. They work on any OS, they are completely transparent, and they cost between 1,000 and 10,000 euros. I did not have one, and buying one to debug a single driver port felt disproportionate.
Wireshark. Supports USB capture on Linux (via usbmon) and Windows (via USBPcap). There is also a macOS XHC20 capture path, but on current macOS it is not the same convenient “start capture, see packets” workflow. In practice it still runs into the same security wall: recent Wireshark guidance points at disabling System Integrity Protection for USB capture on Catalina and later. That put it in the same bucket as dtrace for me: interesting, but not a workflow I wanted for a driver port.
Apple’s Instruments. Has a “USB” trace template, but it records high-level IOKit events — device attach, configuration changes, interface claims. Not bulk transfer payloads. Useless for protocol-level debugging.
The macOS log subsystem. You can enable debug logging for com.apple.usb and com.apple.iokit, but what you get is plugin loading messages, device matching events, and power management transitions. No pipe data.
dtrace. Powerful, kernel-level, could theoretically trace IOKit calls. But on modern macOS, dtrace requires disabling System Integrity Protection — which means rebooting into Recovery Mode, running csrutil disable, rebooting again, doing your trace, then rebooting into Recovery again to re-enable SIP. Even then, many probes are restricted or unavailable in recent macOS versions. Apple has been tightening the screws on dtrace with every release, and it is unclear how long the remaining functionality will survive. I did not want to build my workflow on a tool that requires disabling a core security feature and might stop working entirely next year.
Vendor library debug logging. The library advertises a LOG_USB parameter. I enabled it. No log files were written. Presumably compiled out in the release build.
None of these were viable. I needed another approach.
The IOKit COM interface problem
The vendor library uses the classic IOKit plugin mechanism: it calls IOCreatePlugInInterfaceForService to get an IOCFPlugInInterface, then QueryInterface to get an IOUSBInterfaceInterface. From there, it calls methods like WritePipe, ReadPipe, and ControlRequest through a COM-style vtable.
These vtable calls are indirect — function pointers in a struct, not linked symbols. You cannot interpose the vtable entries just by injecting a library with DYLD_INSERT_LIBRARIES. You also cannot easily patch the vtable, because it lives in read-only memory within the IOUSBLib plugin bundle.
But here is the thing: the synchronous methods I cared about are wrappers around the IOKit user-client call path. Internally, they end up at IOConnectCallMethod — a regular C function exported from IOKit.framework. That function can be interposed.
DYLD interposition
macOS’s dynamic linker supports a mechanism called DYLD_INSERT_LIBRARIES, which lets you inject a shared library into a process at startup. Combined with the __DATA,__interpose section, you can redirect any dynamically linked function call to your own implementation.
The idea is simple:
- Build a small
.dylibthat defines an interposed replacement forIOConnectCallMethod. - In your version, log the arguments and return values.
- Call the real implementation to let the program proceed normally.
- Set
DYLD_INSERT_LIBRARIES=./your_lib.dylibbefore launching the target.
The tricky part is step 3.
Avoiding the original-symbol problem
In many interposition examples, you call the original function via dlsym(RTLD_NEXT, "function_name"). Apple documents exactly that pattern, and for ordinary dependent-library interposition it is the right first thing to try.
For this logger, I wanted something more deterministic. I was interposing a system framework function from an injected library, inside a process that loaded system IOKit plugins and shared-cache code. I had already hit the classic failure mode: resolve what looks like the original, call it, and end up back in the logger. Infinite recursion. Stack overflow. Crash.
I tried a few workarounds:
- Thread-local guard variable — useful for preventing accidental re-entry while logging, but not a way to call the real function if you resolved the wrong address.
- Computing the raw address from
dyld_infoexports — possible in theory, but brittle across macOS updates, shared-cache rebuilds, and chained fixups. - Patching the IOUSBLib vtable directly — probably possible with enough
vm_protectgymnastics, but much more invasive than necessary.
The solution
The key insight is that IOConnectCallMethod and IOConnectCallAsyncMethod are two different exported symbols that both end up in the same IOUserClient external-method machinery. If you only interpose IOConnectCallMethod, you can call through to IOConnectCallAsyncMethod with MACH_PORT_NULL as the wake port. With no async wake port, IOKit takes the synchronous method path — and the dynamic linker routes the call to the real IOConnectCallAsyncMethod, because that symbol was never interposed.
kern_return_t my_IOConnectCallMethod(
mach_port_t c, uint32_t sel,
const uint64_t *si, uint32_t sic,
const void *is, size_t isc,
uint64_t *so, uint32_t *soc,
void *os, size_t *osc)
{
// Log the outbound data
if (isc > 0 && is) hex_dump("OUT", is, isc);
// Call the real implementation via the non-interposed sibling.
// MACH_PORT_NULL keeps this on the synchronous method path.
kern_return_t kr = IOConnectCallAsyncMethod(
c, sel, MACH_PORT_NULL,
NULL, 0, si, sic, is, isc,
so, soc, os, osc);
// Log the inbound response
if (osc && *osc > 0 && os) hex_dump("IN", os, *osc);
return kr;
}
DYLD_INTERPOSE(my_IOConnectCallMethod, IOConnectCallMethod)Build it, inject it, run the vendor’s driver — and the USB traffic that this library sends through IOUSBLib flows through your logger. Control transfers, bulk writes, bulk reads, all of it. No SIP bypass needed. No kernel extension. No hardware USB analyzer. Just 60 lines of C.

What the trace revealed
The trace immediately showed why my driver did not work. Two differences jumped out:
Transfer size. The device operates at USB Full Speed (12 Mbps). Every command I sent was in a 16-byte bulk transfer — the command payload plus a terminator, tightly packed. The vendor’s driver sent every command as a 512-byte transfer request, padded with zeros. That is not a single USB packet on Full Speed; the host controller splits it into endpoint-sized packets. But at the transfer level, the device clearly expected a fixed-size command block. The firmware silently discarded the short writes.
Terminator format. I was using 8 bytes of 0xFF as the end-of-command marker, following what I thought the Linux kernel source was doing. The vendor used a 2-byte marker: a specific opcode value (0x03FF), which is the maximum valid opcode in the protocol — essentially a “no-op, stop processing” sentinel. The 8-byte version was never part of the protocol at all; I had misread the kernel constant.
Neither issue produced an error. The device accepted the USB transfers, returned success codes, and maintained its connection. It just did not execute the commands. Silent failure — the worst kind.

The fix
Once I knew the real wire format, the fix was trivial: build a 512-byte command buffer, pad the unused bytes with zeros, and use the correct 2-byte terminator. The device came alive immediately — green LED, frames flowing, exactly as with the vendor driver.
What I learned
The Linux kernel driver was not wrong. It works perfectly — in the kernel. The kernel’s USB stack submits URBs to the host controller, which handles packetization, short packets, and endpoint details. It will not invent protocol padding for you, though; somewhere in the Linux driver path, the submitted command buffer length was already correct. I missed that because I focused on the command payload and not on the transfer length.
In userspace, with libusb or IOKit, that length is right in your face. If you pass 16 bytes to WritePipe, the device gets a 16-byte transfer. The details that looked like transport trivia suddenly become part of the protocol.
I also learned that “read the open-source driver and reimplement” is not always sufficient. The open-source driver operates in a different environment with different abstractions, and the protocol’s wire-level requirements may be invisible at the source code level. Sometimes you need to look at the actual bytes on the wire — even if that means reverse engineering the one driver that already works.
The DYLD interposition technique is now a permanent tool in my debugging repertoire. It works on the kinds of binaries I usually control — Homebrew-installed tools, local helpers, custom test harnesses — as long as dyld interposition is allowed. SIP-hardened system binaries are excluded. It is not a bus analyzer, and it will not see kernel clients or code paths that bypass the symbol you interpose. But for user-space libraries that talk to IOKit user clients, it can turn an opaque driver into a very useful byte stream. And unlike dtrace, it does not require disabling System Integrity Protection.
Sixty lines of C. That is what stood between “the device does not work” and “here is every byte the working driver sends.” Not bad for an afternoon.
ImpossiBLE — BLE back in the iOS Simulator
For a while, Bluetooth Low Energy in the iOS Simulator was one of those things that half-worked often enough to be useful. It was never a perfect substitute for a real device — Bluetooth never is — but it helped. You could at least keep the edit/build/run cycle on the Mac while working on UI, parsing, state machines, and the boring-but-important parts around the actual radio.
And then, at some point, it was gone.
No dramatic deprecation, no helpful replacement, no grand architectural explanation. Just the usual developer experience where something you had quietly relied on stops being there. CBCentralManager sits in a state that is not useful, scans do not discover anything, and you are back to launching on hardware for every little iteration. If your app talks to BLE hardware, the simulator becomes a very expensive screenshot viewer.
That annoyed me enough to build ImpossiBLE.
The bridge
The original idea is simple: keep your iOS app code unchanged, but intercept the CoreBluetooth calls in the simulator and forward them to a small macOS helper. The helper runs on the Mac, talks to the real Bluetooth controller via CoreBluetooth, and sends the results back over a Unix domain socket.
From the app’s point of view, it still uses CBCentralManager, CBPeripheral, services, characteristics, descriptors, notifications, RSSI, and L2CAP channels. Under the hood, ImpossiBLE swizzles the simulator-side CoreBluetooth entry points and shuttles newline-delimited JSON through /tmp/impossible.sock.
It is not magic. It is just a pragmatic tunnel around a missing feature.

There are a few details that make it pleasant in practice:
- Multiple
CBCentralManagerinstances are handled independently. - Service filters are enforced to match iOS behavior, even where macOS CoreBluetooth is more liberal.
CBManagerStatetracks the socket provider, so starting or stopping the helper produces a usefulpoweredOn/poweredOfftransition.- The simulator side auto-reconnects, so the provider can start before or after the app.
- The app code does not need a special ImpossiBLE mode.
For real hardware, that already gets a lot of day-to-day BLE work back into the simulator.
The mock provider
The new part is that the provider does not have to be real Bluetooth hardware anymore. With ImpossiBLE Mock 2.0.0, the menu bar app has also grown into the control surface I wanted it to be: still small enough to live in the menu bar, but explicit about what is running and what the simulator is doing.
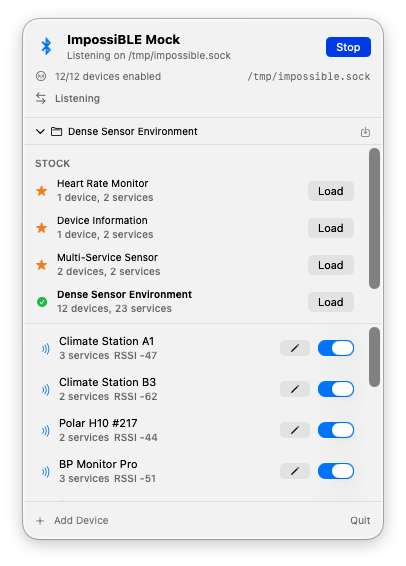
ImpossiBLE ships with a macOS menu bar app called ImpossiBLE Mock. It listens on the same /tmp/impossible.sock socket as the forwarding helper, but instead of talking to the Mac’s Bluetooth hardware it serves virtual peripherals from an editable configuration.
A segmented Off / Mock / Passthrough control at the top switches between modes. Selecting one automatically stops the other, so you never have to worry about which provider is running. The menu bar icon changes to match: a strikethrough Bluetooth symbol when off, the plain symbol when forwarding real hardware, and a dot-badged variant when mocking.
The panel is now a persistent, borderless menu bar window rather than a regular transient menu. It stays open while you switch to the simulator or Xcode, can be toggled from the status item, and remains centered under the menu bar icon. If you prefer classic menu behavior, a Dismiss on Switch setting brings that back.
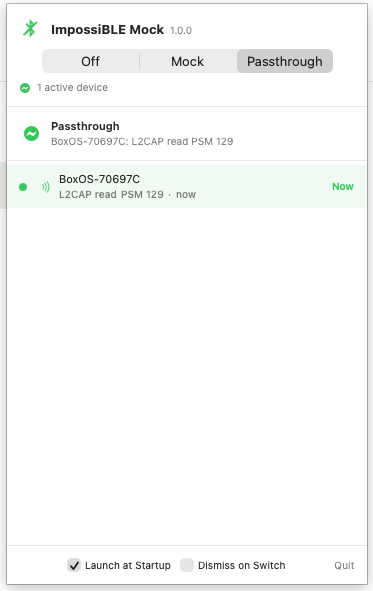
In passthrough mode, the mock device list is replaced by a dedicated status view — no clutter from irrelevant configuration UI. It now shows the devices the simulator app actually talks to. Discovery alone is deliberately not enough to enter the list; a device appears only after real GATT or L2CAP activity such as reads, writes, subscriptions, or channel traffic. If multiple devices are active, the currently communicating one is highlighted with its latest operation and a small Now marker.
The same activity also drives the menu bar icon pulse, so forwarding no longer looks static while real work is happening behind the socket.
In mock mode, the full device editor and configuration management are available.
The iOS app still does not know the difference. It scans, discovers, connects, reads, writes, subscribes, and receives delegate callbacks as usual. Only the provider behind the socket changes.
The mock app comes with a few stock configurations: a heart rate monitor, a device information peripheral, a multi-service sensor, and a dense sensor environment with a dozen devices. You can edit device names, RSSI, connectability, advertised service UUIDs, manufacturer data, services, characteristics, descriptors, characteristic properties, initial values, and simple pairing/security behavior. Custom configurations can be saved and restored. A Launch at Startup checkbox in the footer installs a LaunchAgent, so the app can start automatically at login regardless of where it is installed.
This is especially useful for the parts of BLE development that are usually tedious to reproduce:
- testing scan result ordering and filtering without walking around the room;
- exercising UI states for empty, sparse, and crowded environments;
- checking descriptor discovery and notification setup;
- simulating devices that require pairing or encrypted characteristics;
- keeping a deterministic test setup for demos and screenshots.
The menu bar icon also flashes on socket traffic, which is a tiny thing, but very helpful when you are wondering whether the simulator is actually talking to the provider.
Capturing real devices into mock configurations
Building mock configurations by hand is fine when you know exactly what services and characteristics your target device exposes. But sometimes you just want to grab what is already in the air and turn it into a test fixture.
The mock app now includes a Capture mode that scans for nearby BLE advertisements and lets you cherry-pick devices to include in a new configuration. The scan results are sorted by likely usefulness — devices with more advertised services, names, connectability, and manufacturer data float to the top. Unnamed devices are hidden by default to cut through the noise, but you can reveal them when needed.
When you save a capture, ImpossiBLE goes a step further for connectable devices: it connects to each selected device, discovers its full GATT tree — services, characteristics, descriptors — and reads any values that CoreBluetooth allows. The result is a mock configuration that mirrors what the real device actually exposes, not just what it advertises. Devices that are not connectable or fail to connect are still saved from their advertisement data alone.
This closes a nice loop: scan the room, pick the interesting devices, save, and immediately test against a faithful replica without needing the real hardware powered on.
Installation
The repository is here:
https://github.com/mickeyl/ImpossiBLE
For Homebrew users:
brew install mickeyl/formulae/impossibleThat installs the helper and the mock menu bar app. This is a developer tool, so I am not trying to pretend it is a polished end-user product. The Homebrew formula builds it locally and signs the mock app ad-hoc; if you want a notarized distributable app bundle, the Makefile has the pieces for that as well.
If you prefer to work from the checkout:
git clone https://github.com/mickeyl/ImpossiBLE.git
cd ImpossiBLE
make install
make run # real BLE forwarding
make mock-run # virtual BLE provider
make mock-relaunch # rebuild and reopen the mock menu bar app during developmentOnly run one provider at a time. Both the real helper and the mock app own /tmp/impossible.sock.
Is this a replacement for device testing?
No.
Radio behavior is still radio behavior. Timing, connection stability, hardware quirks, pairing dialogs, background behavior, and all the lovely little platform-specific edge cases still need real devices. ImpossiBLE is not meant to remove that step.
What it does remove is the need to go to hardware for every small iteration. If I am polishing a scan UI, checking a parser, debugging a state machine, or testing how an app reacts to a dense BLE environment, I can now stay in the simulator. That is a big enough win to justify the tunnel, the swizzling, the socket protocol, and the slightly cheeky name.
Apple may have silently taken BLE away from the simulator. Fine. I put it back.
Two million CAN frames and the limits of React
CANcorder, my CAN bus logger and analyzer, is built with Tauri 2 and React 19. It is a desktop app for macOS, Windows, and Linux — written in TypeScript on the frontend, Rust on the backend, and held together by Tauri’s IPC bridge. For the first year of development, this stack felt like a gift. Components are quick to write, state management is straightforward, and the iteration speed of hot-reloading a web view inside a native shell is hard to beat.
Then someone opened a 2.4 million frame CAN log from a vehicle test.

What “fast enough” used to mean
In the early days, the frame table was a straightforward React component. Each visible row was a <div> with child elements for index, timestamp, arbitration ID, DLC, hex data, and ASCII. The ISO-TP (transport message) table was similar, with the additional complexity of expandable protocol hint sections. Both tables used virtual scrolling — the frame table via a hand-rolled implementation, the ISO-TP table via @tanstack/react-virtual — so the browser only ever had to maintain DOM nodes for the rows you could actually see.
For a few thousand frames this was fine. Even for tens of thousands it was workable. But CAN traffic in the real world is not a few thousand frames. A typical bus runs at 500 kbit/s and carries hundreds of frames per second. Record for an hour and you are looking at a million rows. Record a vehicle test session and the number can easily double.
At that scale, the React/DOM approach started to fall apart — not in one dramatic failure, but in a steady accumulation of small costs that added up to big latency.
Death by a thousand DOM nodes
The fundamental problem is not React. React’s reconciliation is actually quite good at what it does. The problem is what lies beneath: the browser’s rendering pipeline.
Every visible row is a subtree of DOM elements. Each element participates in style resolution, layout, paint, and compositing. The virtualizer makes sure only ~30 rows exist at any given time, but scrolling means destroying and creating those subtrees at 60 fps. That means: allocate nodes, attach them to the document, compute styles, run layout, paint layers, composite. Every frame. At every scroll position.
For modest data sets, the browser handles this without breaking a sweat. But when you add row selection highlights, search match indicators, colored arbitration IDs, hex formatting, ASCII previews, and measurement deltas — each with its own element and style — the per-row cost becomes nontrivial. Multiply by the rows that enter and leave the viewport during a single scroll gesture, and you start dropping frames.
The ISO-TP table was worse. It has variable-height rows (expandable hint sections, expandable data previews, status icons), so the virtualizer needed to measure row heights dynamically. That meant even more layout work per scroll event, and the height estimates had to be continuously recalculated as sections were toggled open and closed.
The intermediate steps
Before the big rewrite, I tried the obvious optimizations:
-
Batched frame ingestion. The Rust backend switched from emitting one Tauri event per CAN frame to batching up to 256 frames per event, flushed every 16 ms. The frontend stored incoming frames in refs rather than state, and flushed them to the React render cycle via
requestAnimationFrame. This reduced the number of React re-renders from “one per frame” to “one per animation frame” — a huge win for live capture throughput, but it did not help with scroll performance on large static datasets. -
Memoized row components. Wrapping each row in
React.memoprevented unnecessary re-renders when sibling rows changed. Good practice, but the real cost was not re-rendering existing rows — it was mounting and unmounting rows at the scroll edges. -
Deferred filtering. For large datasets (>50,000 frames), filter computation was split into chunks via
requestAnimationFrameso the UI remained responsive during rebuilds. Again, helpful for filter changes, but orthogonal to scroll performance.
All of these were necessary. None of them were sufficient.
The canvas rewrite
The solution was to stop asking the browser to manage a DOM subtree for every row — and draw the table by hand.
Both FrameTable and IsoTpTable were rewritten from React component trees to imperative Canvas 2D renderers. The React component now owns a single <canvas> element. A FrameTableRenderer class (and its IsoTpTableRenderer counterpart) paints the visible rows directly:
render(scrollTop: number) {
const ctx = this.ctx;
ctx.fillStyle = this.colors.get("table-panel-bg") || "#0f172a";
ctx.fillRect(0, 0, this.width, this.height);
const startIndex = Math.floor(scrollTop / ROW_HEIGHT);
const endIndex = Math.min(
totalRowCount,
Math.ceil((scrollTop + this.height) / ROW_HEIGHT) + 1
);
for (let i = startIndex; i < endIndex; i++) {
// draw row background, indicator, index, timestamp,
// arbitration ID, type, DLC, hex data, ASCII — all via
// fillRect and fillText, no DOM involved
}
}No DOM nodes. No style resolution. No layout engine. No compositing layers per row. Just fillRect and fillText, driven by a scroll offset.
The renderer reads CSS custom properties once (via getComputedStyle) to pick up the theme colors, then paints at native speed. The <canvas> is scaled by devicePixelRatio for crisp text on Retina displays. And because there is only one DOM element — the canvas itself — the browser’s per-frame work is trivially small: composite one layer, done.
Scroll compression
There is a subtle problem that only appears at extreme scale. Browsers impose a maximum scrollable height. In practice it is on the order of tens of millions of pixels, so at 32 pixels per row you can hit it a little past the million-row mark. Past that point, scrollTop values get clamped, and the bottom of the dataset becomes unreachable.
The fix is a scroll compression function:
const MAX_NATIVE_SCROLL_HEIGHT = 33_000_000;
const COMPRESSED_SCROLL_HEIGHT = 250_000;
function createScrollCompression(totalHeight: number, viewportHeight: number) {
if (totalHeight <= MAX_NATIVE_SCROLL_HEIGHT) {
return { enabled: false, /* identity mapping */ };
}
const scrollContentHeight = Math.max(viewportHeight, COMPRESSED_SCROLL_HEIGHT);
return {
enabled: true,
scrollContentHeight,
actualToVirtual: (scrollTop) =>
(scrollTop / (scrollContentHeight - viewportHeight))
* (totalHeight - viewportHeight),
virtualToActual: (scrollTop) =>
(scrollTop / (totalHeight - viewportHeight))
* (scrollContentHeight - viewportHeight),
};
}The invisible scroll content element is clamped to 250,000 pixels. The actual scroll position is mapped linearly to the virtual row space. The user scrolls through a quarter-million-pixel-tall region while the renderer translates that into two-million-row space. In practice this keeps navigation seamless and the scrollbar position meaningful, even though the native thumb size now reflects the compressed range rather than the full virtual height.
Getting work off the main thread
Canvas rendering removed the paint bottleneck, but there were still moments of jank: opening a large file and watching the UI freeze while ECU detection scanned millions of frames.
The ECU detection — counting unique arbitration IDs and their frequencies — was moved to a dedicated Web Worker. The main thread packs the IDs into a transferable Uint32Array buffer, posts it to the worker, and receives the sorted result asynchronously. That moves the heavy counting work off the UI thread and avoids an extra copy during transfer.
// ecu-count.worker.ts
self.onmessage = (event) => {
const ids = new Uint32Array(event.data.ids, 0, event.data.length);
const counts = new Map<number, number>();
for (let i = 0; i < ids.length; i++) {
const id = ids[i];
counts.set(id, (counts.get(id) || 0) + 1);
}
self.postMessage({ ecus: sortCounts(counts) });
};Similarly, search across millions of frames now uses chunked processing with requestAnimationFrame boundaries. The search input is debounced by 750 ms so that each keystroke does not trigger a full-dataset scan. And when no filters are active, the renderer reads directly from the raw frame array — skipping the cost of building a filtered copy entirely.
What I learned
The Tauri/React stack is genuinely excellent. For 90% of desktop app UI work, it is productive, portable, and fast enough. But “fast enough” has a ceiling, and for high-frequency, high-density data tables, that ceiling is the browser’s DOM rendering pipeline.
The realization was not new to me — a few weeks ago I went through the same arc on iOS, moving from SwiftUI to UIKit to hand-drawn draw(_ rect:) cells. The pattern is identical: high-level frameworks make the common case easy, but when you need to scroll through a million rows of monospaced hex at 60 fps, there is no substitute for owning the pixel pipeline.
What was new is that the web platform actually lets you do this. Canvas 2D is fast, well-supported, and plays nicely with the rest of the React component tree. The table is a canvas, but the toolbar, filter panel, connection panel, and every other part of the UI remain normal React components. You do not have to throw out the framework to escape its hot path.
The takeaway is simple: if your data table has more rows than a spreadsheet, stop asking the DOM to be a spreadsheet.
Back to UIKit for fluid scrolling
I have spent the last couple of days optimizing the iPhone companion app for CANcorder (forthcoming), my CAN bus logger and analyzer. The original iOS frontend was written in SwiftUI, which made it wonderfully quick to build and iterate on. For modest amounts of data, it was fine. But “modest” is not what CAN traffic looks like in the real world. Once I attached an ECU that happily sprayed roughly 700 frames per second, the app started to tell a very old story again: pretty abstractions are no substitute for ruthless control over the hot path.
What surprised me is not that SwiftUI eventually hit a wall. What surprised me is where the big win came from. Moving from SwiftUI to UIKit was already worthwhile, but the really major step towards fluid scrolling on modern iPhones came only after going one step further: skipping stack views, skipping Auto Layout, and drawing the rows by hand.
Yes, even on today’s ridiculously powerful devices.

SwiftUI is excellent until it is not
SwiftUI is fantastic for the 90% case. If your list has a few hundred rows, occasional updates, and a reasonably static layout, I would still pick it first. The API is productive, state propagation is elegant, previews are pleasant, and you can ship features very quickly.
But a live log viewer with tens of thousands of rows is not the 90% case.
My first implementation used a SwiftUI list-like hierarchy. It worked, but it did too much work on every update: view diffing, text layout, filter recomputation, derived state rebuilding, and all the other little conveniences that feel cheap when the data set is small. Once the frame count climbed into the tens of thousands, scrolling became choppy. Around the six-figure mark, it was obvious that this was not the right tool for the job.
The first refactoring was predictable: move parsing, ISO-TP decoding, filtering, and export work off the main thread. That helped, and it was necessary anyway. But it still did not feel right. The UI was better, not fluid.
UIKit was necessary, but not sufficient
The next step was replacing the SwiftUI row hierarchy with UITableView. That alone already cut a lot of overhead. Cell reuse is still a wonderfully boring and effective idea. There is a reason it has survived so many framework cycles.
However, my first UIKit version was still far from optimal. The cells used UILabel, UIImageView, UIStackView, and constraints. In other words, I had merely replaced one high-level layout system with another slightly older one. This version was better than SwiftUI, yes, but under sustained live ingest it still felt heavier than it should.
This is the version that looked correct on paper:
private final class IsoTpTableCell: UITableViewCell {
private let iconView = UIImageView()
private let idLabel = UILabel()
private let metaLabel = UILabel()
private let hintLabel = UILabel()
private let dataLabel = UILabel()
override init(style: UITableViewCell.CellStyle, reuseIdentifier: String?) {
super.init(style: style, reuseIdentifier: reuseIdentifier)
let topRow = UIStackView(arrangedSubviews: [idLabel, UIView(), metaLabel])
topRow.axis = .horizontal
let textStack = UIStackView(arrangedSubviews: [topRow, hintLabel, dataLabel])
textStack.axis = .vertical
textStack.spacing = 2
textStack.translatesAutoresizingMaskIntoConstraints = false
contentView.addSubview(iconView)
contentView.addSubview(textStack)
NSLayoutConstraint.activate([
iconView.leadingAnchor.constraint(equalTo: contentView.layoutMarginsGuide.leadingAnchor),
textStack.leadingAnchor.constraint(equalTo: iconView.trailingAnchor, constant: 10),
textStack.trailingAnchor.constraint(equalTo: contentView.layoutMarginsGuide.trailingAnchor),
])
}
}There is nothing wrong with that code. In fact, for most apps it is perfectly reasonable. But when you want to scroll through 10,000 or 100,000 rows while ingesting live data, every one of those conveniences has a cost. Constraints need solving, views need layout, labels need text measurement, and the cell tree is much larger than the pixels you actually need to paint.
The major step was getting rid of layout machinery
The real breakthrough came when I stopped asking UIKit to build and lay out a mini view hierarchy for every visible row.
Instead, each reusable cell now hosts a tiny canvas view. That canvas measures the available width once per width bucket, chooses the largest monospaced font size that still guarantees visibility of all eight CAN data bytes, and draws the text directly.
No labels. No stack views. No constraints. No Auto Layout.
private final class FrameTableCell: UITableViewCell {
private let canvasView = FrameRowCanvasView()
override init(style: UITableViewCell.CellStyle, reuseIdentifier: String?) {
super.init(style: style, reuseIdentifier: reuseIdentifier)
selectionStyle = .none
contentView.addSubview(canvasView)
canvasView.autoresizingMask = [.flexibleWidth, .flexibleHeight]
}
override func layoutSubviews() {
super.layoutSubviews()
canvasView.frame = contentView.bounds
}
}And the actual row rendering is little more than measured rectangles and direct drawing:
override func draw(_ rect: CGRect) {
guard let frameModel else { return }
let metrics = Self.metrics(for: bounds.width)
let contentRect = bounds.insetBy(dx: 8, dy: 6)
let idRect = CGRect(x: contentRect.minX, y: contentRect.minY,
width: metrics.leftColumnWidth, height: metrics.idFont.lineHeight)
let dataRect = CGRect(x: contentRect.minX + metrics.leftColumnWidth + 8,
y: contentRect.midY - metrics.dataFont.lineHeight / 2,
width: metrics.dataColumnWidth,
height: metrics.dataFont.lineHeight)
frameModel.formattedId.draw(in: idRect, withAttributes: idAttributes)
frameModel.visibleDataText.draw(in: dataRect, withAttributes: dataAttributes)
}The font fitting is similarly simple and similarly important:
private static func metrics(for width: CGFloat) -> LayoutMetrics {
let availableWidth = max(0, width - 16)
let template = "00 00 00 00 00 00 00 00"
var size: CGFloat = 16
while size >= 10 {
let dataFont = UIFont.monospacedSystemFont(ofSize: size, weight: .medium)
let dataWidth = ceil((template as NSString).size(withAttributes: [.font: dataFont]).width)
if dataWidth <= availableWidth {
return LayoutMetrics(dataFont: dataFont, dataColumnWidth: dataWidth)
}
size -= 0.5
}
return LayoutMetrics(dataFont: .monospacedSystemFont(ofSize: 10, weight: .medium),
dataColumnWidth: 150)
}This may look primitive compared to SwiftUI’s declarative charm, but that is precisely the point: primitive code leaves less work for the runtime.
The other half: only UI on the main thread
There is another rule that became non-negotiable during this exercise: the main thread should do UI, and only UI. Not “mostly UI”. Not “UI plus a little convenience formatting”. UI.
That means:
- TCP receive off the main thread
- CAN frame parsing off the main thread
- ISO-TP decoding off the main thread
- filtering off the main thread
- CSV export off the main thread
- row string precomputation off the main thread
By the time the table view sees a row model, the expensive work is already done. The cell should not need to wonder how to turn bytes into text or whether a frame is interesting. It should just paint the answer.
The row model now comes prepared:
struct CANFrame: Identifiable, Equatable, Sendable {
let formattedId: String
let visibleDataText: String
let asciiPreviewText: String
let shortTimestamp: String
init(index: Int, timestamp: UInt64, canId: UInt32, extended: Bool, dlc: UInt8, data: [UInt8]) {
self.formattedId = extended ? String(format: "%08X", canId) : String(format: "%03X", canId)
self.visibleDataText = data.prefix(8).map { String(format: "%02X", $0) }.joined(separator: " ")
self.asciiPreviewText = String(data.prefix(8).map { $0 >= 0x20 && $0 < 0x7F ? Character(UnicodeScalar($0)) : "." }.prefix(8))
self.shortTimestamp = String(format: "%.3f", Double(timestamp) / 1_000_000.0)
}
}Again, none of this is intellectually sophisticated. It is just disciplined.
Modern hardware does not save wasteful UI code
It is tempting to believe that an A‑series iPhone chip should brute-force its way through anything. And indeed, modern devices hide a multitude of sins. But they do not repeal the laws of software physics. If you ask the framework to solve constraints, diff view trees, measure text repeatedly, allocate too many subviews, and do too much work during rapid updates, you will still pay for it.
The key lesson here is that UI performance is not usually lost in one dramatic mistake. It leaks away in death by a thousand abstractions. Each one seems harmless. Together they turn “should feel instant” into “why is this slightly sticky?”
And when you strip those abstractions away, the result can be almost embarrassingly better.
Conclusion
I still like SwiftUI. I will continue to use SwiftUI for many parts of iOS apps, because the productivity gains are real and often worth the tradeoff. But for high-frequency, very large, log-style interfaces on the iPhone, I am now more convinced than ever that going back to UIKit is only half the journey. The major step towards truly fluid scrolling is to keep UIKit on a very short leash: reuse cells, avoid Auto Layout in the hot path, measure once, and draw by hand.
Apparently, even in 2026, the old tricks are still the fast ones.
From Lektor to Zola — migrating 26 years of content
This website has been running on Lektor, a Python-based static site generator created by Armin Ronacher (of Flask fame), since I moved away from WordPress years ago. Lektor served me well: its file-based content model, Jinja2 templates, and simple admin UI were a good fit for a personal site that doesn’t need a database.
But over the past year, the cracks became impossible to ignore.

Why leave Lektor?
Lektor is effectively on life support. The project’s own developers describe it as being in maintenance mode. The two remaining part-time maintainers can barely keep up with dependency rot, let alone ship new features. Version 3.4 has been stuck in beta for over three years — and it contains the fixes for the pkg_resources deprecation warnings that have been plaguing every build since Python 3.12.
Every time I ran lektor build, I was greeted by a wall of deprecation warnings from werkzeug, setuptools, and mistune. The plugin ecosystem is stagnant, community activity is near zero (~4,600 PyPI downloads/month), and the next Python or setuptools release could break the build with nobody upstream to fix it. I’d rather migrate on my own terms than be forced to do it in a hurry.
Why Zola?
I evaluated Hugo, Eleventy, Astro, and Zola. The deciding factor was template compatibility: Zola uses Tera, a Rust-based template engine whose syntax is nearly identical to Jinja2. That meant I could port my templates with minimal rewriting rather than learning Go’s template language (Hugo) or switching to JSX (Astro).
Other things I like about Zola:
- Single binary, no runtime dependencies.
brew install zolaand you’re done. No Python virtualenvs, no npm, no Ruby gems. - Fast. My 279-page site builds in under 800ms. Lektor took several seconds.
- Built-in Sass compilation, syntax highlighting, feeds, and sitemaps. No plugins needed for the basics.
- Smart punctuation. Zola can automatically convert straight quotes and triple dots to their typographic equivalents — a feature dear to my typographer’s heart.
The migration
The actual work broke down into a few steps:
Templates. Tera is close enough to Jinja2 that most of my templates needed only minor adjustments. The main gotcha: Tera doesn’t support nested array literals in {% for %} loops, so I had to unroll my navigation loop into explicit <li> elements. A fair trade for the performance gain.
Content. I wrote a Python script that converts Lektor’s .lr format (field-based with --- separators) to Markdown with TOML frontmatter (+++ delimiters). 266 blog posts, plus all section pages, migrated automatically. One subtlety: Lektor allows multiple single-line fields in the same block without separators — the parser needed to handle that.
CommonMark differences. Lektor’s Markdown renderer was more lenient about mixing HTML and Markdown on adjacent lines. In CommonMark (which Zola uses), an <img> tag starts an HTML block that swallows everything until a blank line. I had to insert blank lines after every <img> that was followed by a Markdown heading — about 15 instances across the code, music, and words sections.
Typography audit. While migrating, I scanned all 266 posts for typographic issues. A script replaced 253 instances of ASCII triple dots with proper ellipsis characters (…). The older posts — some dating back to 1999 — had accumulated quite a bit of cruft.
Link audit. I checked all 865 external links. About 200 domains are dead, mostly from the OpenMoko/embedded Linux era (2006–2011). Domains like openmoko.org, trolltech.com, and code.google.com/soc are gone. These are historical blog posts, so I’m leaving them as-is rather than littering them with Wayback Machine URLs.
Deploy. The old Lektor deploy used lektor build && lektor deploy (which called rsync internally). The new deploy is simply zola build followed by a direct rsync to the server. The CANcorder manifest generation and version injection pipeline carried over unchanged.
Result
Same content, same URLs, same visual identity — but a build system that will actually survive the next Python release. And builds that finish before I can reach for my coffee!